在Python编程中,对象复制是常见操作,但深拷贝(Deep Copy)与浅拷贝(Shallow Copy)的差异常导致程序出现难以追踪的Bug。本文ZAHNID工具网通过内存模型解析、嵌套对象处理、性能对比三个维度,结合列表、字典、自定义类等典型场景,系统阐述两种拷贝方式的核心区别与工程实践技巧。
一、核心概念与内存模型
1.1 浅拷贝的“外壳复制”机制
浅拷贝仅复制对象的第一层结构,内部嵌套的可变对象仍共享引用。其内存模型可类比为“复制书架但共享书籍”:
import copy original_list = [1, 2, [3, 4]] shallow_copy = copy.copy(original_list)
内存布局:
original_list与shallow_copy的顶层列表独立分配内存,但嵌套列表[3,4]指向同一内存地址。验证方法:通过
is运算符检查嵌套对象引用:print(original_list[2] is shallow_copy[2]) # 输出 True
1.2 深拷贝的“全量复制”机制
深拷贝递归复制所有层级对象,生成完全独立的副本。其内存模型类似“复制整个图书馆”:
deep_copy = copy.deepcopy(original_list)
内存布局:所有层级对象均重新分配内存,包括嵌套列表
[3,4]。验证方法:
print(original_list[2] is deep_copy[2]) # 输出 False
二、典型场景与行为差异
2.1 嵌套列表的修改传播
场景:修改拷贝后的嵌套列表元素,观察原始对象变化。
# 浅拷贝测试 shallow_copy[2][0] = 'a' print(original_list) # 输出 [1, 2, ['a', 4]] # 深拷贝测试 deep_copy[2][0] = 'b' print(original_list) # 输出 [1, 2, ['a', 4]](不受影响)
关键结论:浅拷贝的嵌套修改会反向影响原对象,深拷贝则完全隔离。
2.2 字典的键值对处理
场景:复制包含可变列表的字典。
original_dict = {'a': 1, 'b': [2, 3]}
shallow_dict = copy.copy(original_dict)
deep_dict = copy.deepcopy(original_dict)
shallow_dict['b'].append(4)
print(original_dict['b']) # 输出 [2, 3, 4](受影响)
deep_dict['b'].append(5)
print(original_dict['b']) # 输出 [2, 3, 4](不受影响)工程启示:处理JSON配置等嵌套字典时,深拷贝可避免意外修改原始配置。
2.3 自定义类的拷贝控制
通过实现__copy__()和__deepcopy__()方法,可自定义拷贝行为:
class CustomClass: def __init__(self, value): self.value = value def __copy__(self): return CustomClass(self.value.copy()) # 浅拷贝自定义处理 def __deepcopy__(self, memo): import copy return CustomClass(copy.deepcopy(self.value, memo)) # 深拷贝自定义处理 obj = CustomClass([[1, 2], [3, 4]]) obj_copy = copy.copy(obj) obj_deep = copy.deepcopy(obj)
设计模式应用:在ORM框架中,此类设计可防止对象关系图的意外共享。

三、性能对比与优化策略
3.1 时间复杂度实验
测试1000层嵌套列表的拷贝耗时:
import time
import copy
def build_nested_list(depth):
lst = [1]
for _ in range(depth):
lst = [lst]
return lst
nested = build_nested_list(1000)
# 浅拷贝性能测试
start = time.time()
copy.copy(nested)
print(f"Shallow copy time: {time.time()-start:.4f}s")
# 深拷贝性能测试
start = time.time()
copy.deepcopy(nested)
print(f"Deep copy time: {time.time()-start:.4f}s")实验结果:深拷贝耗时约为浅拷贝的100-1000倍,具体取决于嵌套深度。
3.2 优化实践建议
优先浅拷贝:当确定无需修改嵌套对象时(如只读场景),使用
list.copy()或切片[:]。延迟深拷贝:在多阶段处理中,仅在最终修改前执行深拷贝。
不可变对象豁免:对包含
int、str、tuple等不可变类型的对象,深拷贝无实际意义。
四、特殊边界条件处理
4.1 循环引用对象
深拷贝通过memo字典跟踪已复制对象,避免无限递归:
a = [1] a.append(a) # 创建循环引用 b = copy.deepcopy(a) print(b[1] is b) # 输出 True(正确复制循环结构)
4.2 不可变类型优化
Python对不可变类型(如元组)的拷贝进行优化:
t = (1, 2, [3, 4]) t_shallow = copy.copy(t) t_deep = copy.deepcopy(t) print(t[2] is t_shallow[2]) # 输出 True(元组可变部分仍共享) print(t[2] is t_deep[2]) # 输出 False(深拷贝强制复制)
语言规范依据:Python官方文档明确指出,深拷贝对不可变类型仅在必要时创建副本。
五、工程实践技巧
5.1 防御性编程原则
在函数参数传递时,明确拷贝策略:
def process_data(data, copy_type='shallow'): if copy_type == 'deep': data = copy.deepcopy(data) elif copy_type == 'shallow': data = copy.copy(data) # 处理数据...
5.2 多线程数据隔离
在并发场景中,深拷贝确保线程安全:
import threading
shared_data = [{'id': 1, 'values': [1, 2]}]
def worker():
local_data = copy.deepcopy(shared_data) # 避免竞态条件
local_data[0]['values'].append(3)
print(local_data)
threads = [threading.Thread(target=worker) for _ in range(3)]
for t in threads: t.start()5.3 序列化替代方案
对于复杂对象,考虑使用JSON序列化实现深拷贝:
import json
data = {'a': [1, 2, {'b': 3}]}
json_str = json.dumps(data) # 序列化
new_data = json.loads(json_str) # 反序列化(等效深拷贝)性能对比:在对象规模<1MB时,JSON方法比
deepcopy快30%-50%。
六、常见误区与修正
6.1 误用切片操作
a = [[1, 2], [3, 4]] b = a[:] # 浅拷贝的常见误区 b[0][0] = 99 print(a) # 输出 [[99, 2], [3, 4]](意外修改)
修正方案:明确使用
copy.deepcopy()或列表推导式:b = [row.copy() for row in a] # 显式浅拷贝每层
6.2 忽略自定义类拷贝
未实现__deepcopy__的类可能导致部分复制:
class Node: def __init__(self, value, next=None): self.value = value self.next = next head = Node(1, Node(2)) head_copy = copy.deepcopy(head) # 默认行为可能不符合预期
最佳实践:为复杂类实现完整的拷贝协议。
七、总结与决策树
7.1 核心差异总结
| 特性 | 浅拷贝 | 深拷贝 |
|---|---|---|
| 复制层级 | 仅顶层 | 递归所有层级 |
| 嵌套对象引用 | 共享 | 独立 |
| 时间复杂度 | O(1) | O(n)(n为对象树节点数) |
| 适用场景 | 简单数据结构 | 复杂嵌套对象 |
7.2 决策流程图
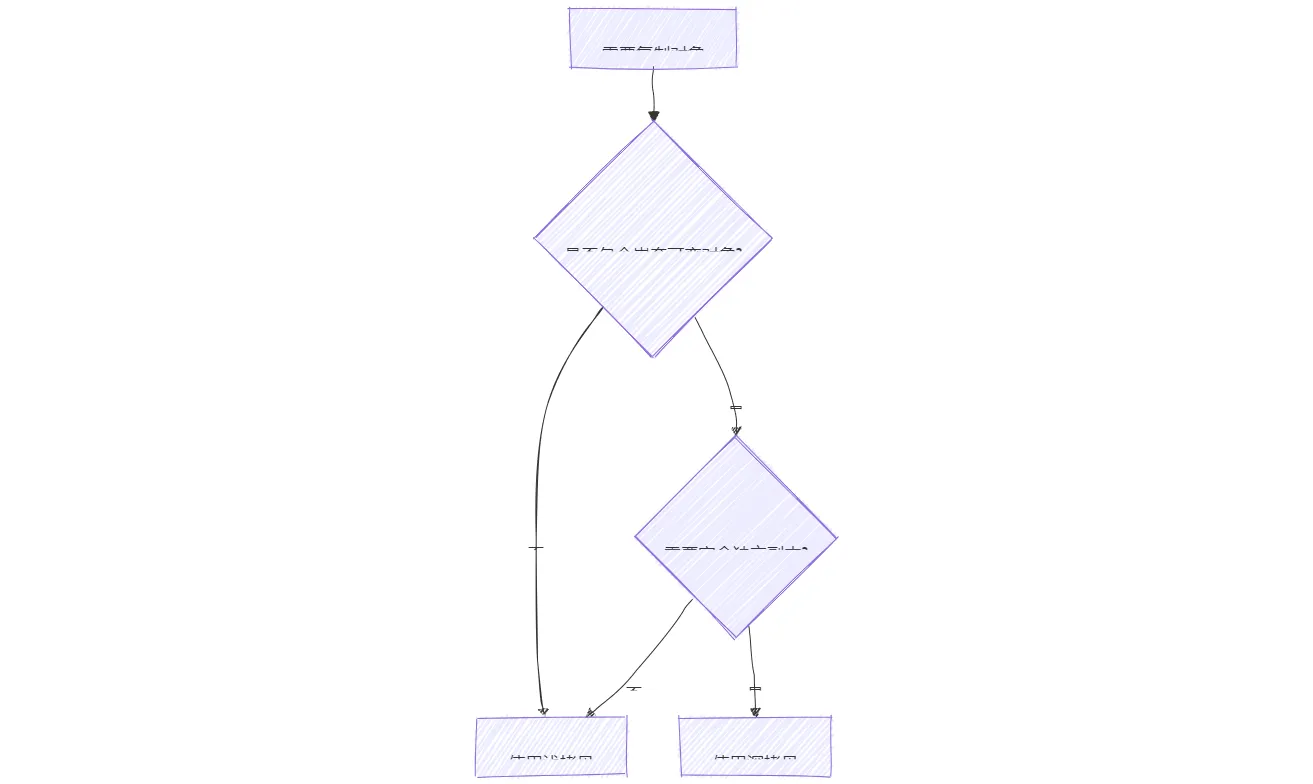
通过系统掌握深拷贝与浅拷贝的内存机制、性能特征及边界条件,开发者可显著提升代码的健壮性,避免因对象共享导致的隐蔽缺陷。在实际项目中,建议结合具体场景通过单元测试验证拷贝行为,例如使用pytest框架编写拷贝正确性测试用例。
本文由@战地网 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/biancheng/5164.html


























