Hallo是什么
Hallo,全称为“Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation”,是一项由复旦大学、百度公司、苏黎世联邦理工学院和南京大学联合开发的革命性AI技术。这项技术通过用户上传的照片,结合语音输入,能够生成高度逼真且动态的肖像动画,实现嘴唇同步、表情变化和姿态调整,极大地丰富了数字内容创作的可能性和互动性。Hallo不仅超越了传统动画制作的限制,还以其独特的分层音频驱动视觉合成模块,在图像和视频质量、唇部同步精度以及运动多样性方面取得了显著突破。
功能特色
高度逼真的动画效果: Hallo利用先进的音频分析技术和视觉合成模块,能够精准捕捉语音中的情感变化和语调特征,生成与之匹配的面部表情和嘴唇动作,使得动画角色仿佛真人在说话,极大地提升了观众的沉浸感和代入感。
个性化定制: 该技术允许用户根据应用场景和个人特征,对动画的表情和姿态进行适应性控制,满足多样化的视觉和情感表达需求。无论是商业宣传、数字娱乐还是教育领域,Hallo都能提供贴合需求的个性化动画解决方案。
分层音频驱动视觉合成: Hallo采用分层结构来处理音频输入和视觉输出,将唇部、表情和头部姿态等动画元素独立控制,使得每一层都能达到最佳效果。这种设计不仅提高了动画的自然度,还增强了动画的多样性和灵活性。
高效便捷的操作流程: 用户只需上传一张照片和相应的语音文件,Hallo即可自动完成动画的生成过程,无需复杂的配置或专业技能。这种高效便捷的操作流程,使得Hallo成为广大用户和内容创作者的首选工具。
广泛的兼容性和可扩展性: Hallo支持多种音频和视频格式,能够与现有的数字内容创作工具无缝对接。同时,其开放式的架构和可扩展的插件系统,也为未来的功能升级和技术创新提供了广阔的空间。
技术细节
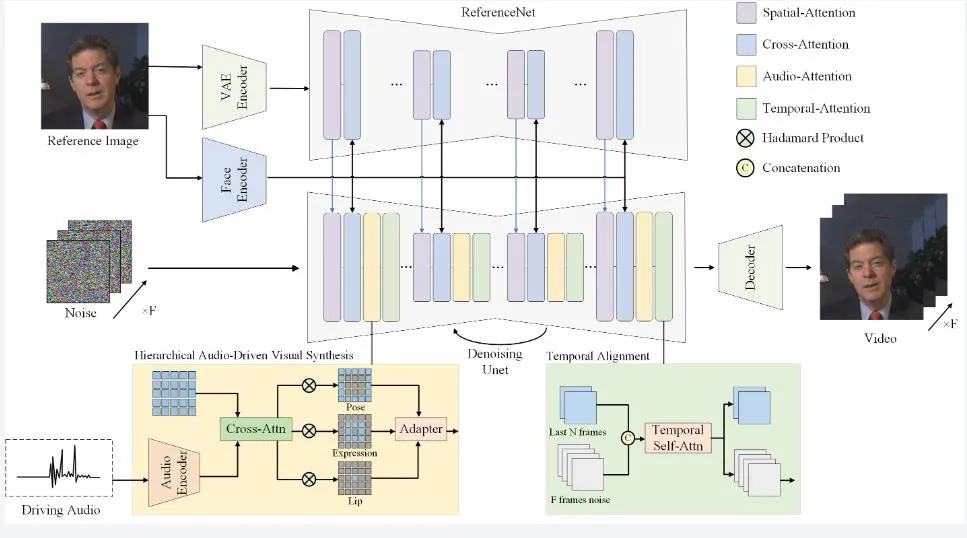
基于扩散的生成模型: Hallo采用了基于扩散的方法论框架,通过逐步引入噪声并学习去噪过程,生成高质量的图像和视频。这种方法不仅提高了生成结果的多样性,还使得动画在细节上更加逼真和自然。
UNet去噪器: 为了进一步提升动画质量,Hallo引入了一个基于UNet的去噪器。该去噪器能够有效地去除动画中的噪声和伪影,使得动画画面更加清晰和纯净。
时间对齐技术: 为了实现音频与视觉输出的高度同步,Hallo采用了先进的时间对齐技术。该技术能够自动调整动画的节奏和速度,确保嘴唇动作与语音音频的精确匹配。
交叉注意力机制: Hallo的核心是“交叉注意力机制”,它在音频输入和视觉输出之间建立了精确的对应关系。这种机制使得动画能够根据语音信号的变化实时调整表情和姿态,实现更加自然和流畅的动画效果。
参考网络: 为了提升动画的多样性和真实感,Hallo还引入了一个参考网络。该网络能够学习不同个体和场景下的动画特征,为生成的动画提供丰富的参考素材和灵感来源。
应用场景
经典电影配音: 在电影后期制作中,Hallo可以用于为经典角色配音或重新制作对话场景。通过上传角色的照片和配音演员的语音文件,Hallo能够生成与角色形象高度匹配的动画效果,为观众带来全新的观影体验。
虚拟形象发声: 在游戏、动漫等虚拟世界中,Hallo可以用于生成虚拟角色的动画效果。通过为虚拟角色上传照片并录制语音文件,Hallo能够赋予虚拟角色生动的表情和动作,增强虚拟世界的真实感和互动性。
真实形象发声: 在社交媒体、直播等领域,Hallo可以用于生成用户的真实形象动画。用户只需上传自己的照片并录制语音消息,Hallo即可生成与用户形象匹配的动画效果,提升用户表达的趣味性和生动性。
动作控制: 在动画制作和特效制作中,Hallo可以用于实现精细的动作控制。用户可以根据需求调整动画中角色的头部姿态、手势等动作细节,实现更加精准和丰富的动画效果。
图片人物唱歌: 在音乐视频或MV制作中,Hallo可以用于生成图片人物唱歌的动画效果。用户只需上传人物照片和音乐文件,Hallo即可根据音乐的节奏和情感变化生成相应的动画效果,为音乐视频增添更多趣味性和观赏性。
跨角色演员: 在戏剧、舞台剧等领域,Hallo可以用于实现跨角色的演员替换。通过上传不同角色的照片和语音文件,Hallo能够生成与各个角色形象匹配的动画效果,实现演员之间的无缝切换和角色转换。

相关官方链接
Hallo官方项目网址:https://fudan-generative-vision.github.io/hallo/
总结
Hallo作为一项革命性的AI技术,通过其独特的分层音频驱动视觉合成模块和先进的生成模型,为肖像图像动画领域带来了前所未有的创新和突破。无论是从动画效果的真实性、个性化定制的能力还是操作流程的便捷性来看,Hallo都展现出了巨大的潜力和优势。随着技术的不断发展和完善,相信Hallo将在数字娱乐、教育、虚拟助手等多个领域发挥更加重要的作用,为用户带来更加丰富、沉浸式的视听体验。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2278.html


























