在人工智能技术日新月异的今天,语音识别与转录技术已成为众多行业不可或缺的一部分。然而,随着语音数据的广泛应用,如何有效保护用户隐私成为了一个亟待解决的问题。近期,aiOla宣布推出了一款名为Whisper-NER的开源AI音频转录模型,该模型在转录过程中能够实时遮蔽敏感信息,为语音识别领域带来了革命性的变化。本文ZHANID工具网将深入介绍Whisper-NER是什么、其功能特色、技术细节及应用场景。
一、Whisper-NER是什么
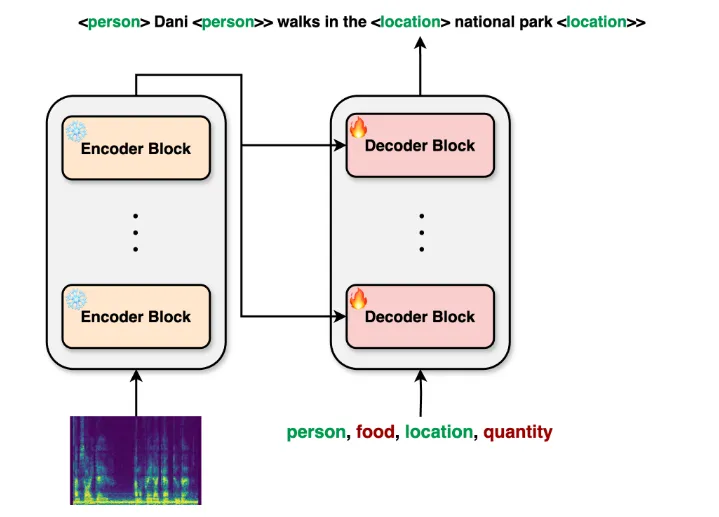
Whisper-NER是aiOla基于OpenAI的开源语音识别模型Whisper开发的一款高级音频转录模型。它不仅继承了Whisper在多语言、实时处理及高准确度方面的卓越性能,还创新性地加入了敏感信息遮蔽功能。这意味着,在转录音频文件时,Whisper-NER能够自动识别并隐藏如个人姓名、地址、电话号码等敏感信息,从而有效防止隐私泄露。
二、功能特色
1. 实时敏感信息遮蔽
Whisper-NER的核心功能在于其实时敏感信息遮蔽能力。用户在使用该模型进行音频转录时,可以根据需要选择是否启动遮蔽功能。一旦启动,模型将自动分析转录文本,识别并隐藏所有潜在的敏感信息。这种能力对于需要处理大量含有个人隐私数据的行业尤为重要,如法律、医疗和教育领域。
2. 多语言与口音支持
得益于Whisper的基础架构,Whisper-NER同样支持多种语言和口音。无论是英语、中文、法语还是德语,该模型都能准确地进行语音识别和转录。这种跨语言的支持使得Whisper-NER在全球范围内的应用变得更为广泛和实用。
3. 高效准确的转录性能
Whisper-NER在保持敏感信息遮蔽功能的同时,并未牺牲其转录的准确性和效率。模型采用了先进的深度学习算法,能够实时处理音频输入,并快速生成高质量的转录文本。这种高效准确的转录性能使得用户能够在各种复杂场景下高效地使用该模型。
4. 开源与可定制性
Whisper-NER是完全开源的,用户可以在Hugging Face和Github上获取其源代码,并根据自身需求进行修改和优化。这种开源特性不仅提升了模型的可用性,还促进了AI技术的创新和发展。开发者和研究人员可以利用这一平台,进一步探索和优化敏感信息遮蔽技术,推动该领域的技术进步。
三、技术细节
1. 基于Whisper的架构
Whisper-NER构建在OpenAI的开源语音识别模型Whisper之上。Whisper采用了Transformer序列到序列模型,通过在大规模多样化的音频数据集上进行训练,实现了多任务处理的能力,包括多语言语音识别、语音翻译和语言识别等。这种强大的基础架构为Whisper-NER提供了坚实的技术支撑。
2. 敏感信息识别算法
为了实现实时敏感信息遮蔽功能,Whisper-NER采用了先进的自然语言处理(NLP)技术。模型内置了一套敏感信息识别算法,该算法能够分析转录文本中的词汇和上下文信息,从而准确识别出个人姓名、地址、电话号码等敏感信息。一旦识别到敏感信息,算法将自动将其替换为占位符或隐藏符号,以保护用户隐私。
3. 多任务学习与优化
Whisper-NER在训练过程中采用了多任务学习的方法。通过将敏感信息遮蔽与语音识别任务联合优化,模型能够在保证转录准确性的同时,提高敏感信息识别的准确率和效率。此外,用户还可以根据实际需求对模型进行进一步的优化和调整,以适应不同的应用场景和需求。
四、应用场景
1. 法律领域
在法律领域,音频转录是律师和法官处理案件时不可或缺的一部分。然而,由于音频文件中往往包含大量敏感信息,如证人证言、被告人供述等,如何保护这些信息不被泄露成为了一个重要问题。Whisper-NER的出现解决了这一难题,它能够在转录过程中实时遮蔽敏感信息,确保案件处理的公正性和安全性。
2. 医疗领域
在医疗领域,医生需要与患者进行频繁的语音交流以获取病情信息。然而,这些交流内容往往包含患者的个人隐私信息,如姓名、病情、治疗方案等。使用Whisper-NER进行音频转录时,可以自动遮蔽这些敏感信息,保护患者的隐私权益。同时,转录后的文本还可以作为医疗记录的一部分进行保存和分析,提高医疗服务的质量和效率。
3. 教育领域
在教育领域,音频转录技术被广泛应用于课堂录制、在线会议和远程教学等场景。然而,在这些场景中同样存在敏感信息泄露的风险。例如,在线会议中可能包含学生的个人信息或讨论内容等敏感信息。使用Whisper-NER进行音频转录时,可以确保这些信息不被泄露出去,保护学生的隐私权益。同时,转录后的文本还可以作为教师备课和教学评估的重要参考依据。
五、相关官方链接
Hugging Face 链接:https://huggingface.co/aiola/whisper-ner-v1
Github 链接:https://github.com/aiola-lab/whisper-ner
用户可以在上述链接中获取Whisper-NER的源代码、模型文件和相关文档资源。同时,也可以在开源平台上与其他开发者和研究人员交流心得、分享经验,共同推动该技术的发展和进步。
总结
Whisper-NER作为一款开源的AI音频转录模型,在保护用户隐私方面展现出了卓越的性能和潜力。其实时敏感信息遮蔽功能使得该模型在法律、医疗和教育等领域的应用场景中显得尤为重要。同时,该模型的开源特性和可定制性也为开发者和研究人员提供了广阔的创新空间。随着技术的不断进步和应用的不断拓展,相信Whisper-NER将在未来发挥更加重要的作用,为AI技术的创新和发展贡献更多的力量。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2373.html


























