EchoMimicV2是什么
EchoMimicV2是由蚂蚁集团的终端技术部门开发的一款先进的人类动画生成模型。作为EchoMimic系列的最新迭代,V2版本在功能和性能上实现了显著提升,专注于生成高质量的半身人类动画。通过音频驱动技术,EchoMimicV2能够捕捉音频中的信息,并将其转化为生动、自然的动画效果,极大地丰富了动画的表现力和真实感。
功能特色
EchoMimicV2在功能设计上展现出了诸多亮点,这些功能特色共同构成了其强大的动画生成能力。
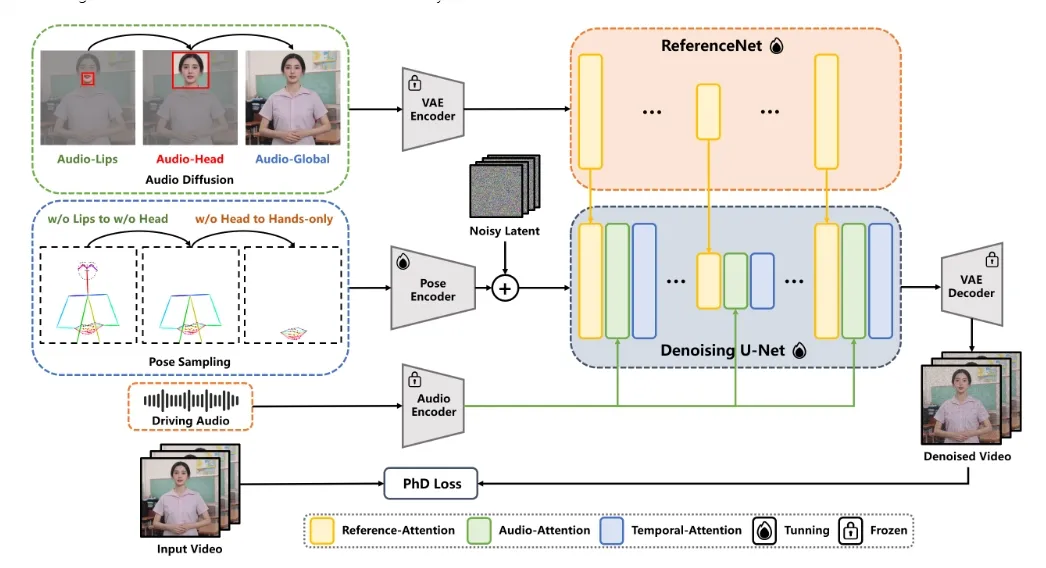
1. 音频姿势动态协调策略
EchoMimicV2采用了一种新颖的音频姿势动态协调策略,该策略结合了姿势采样和音频扩散技术,旨在增强半身动画的细节表现、面部表情和手势动作的真实感。通过这一策略,模型能够更准确地捕捉音频中的语调、节奏和情绪变化,并将其映射到动画角色的动作和表情上,从而实现音频与动画的紧密同步和高度协调。
2. 头部局部注意力机制
针对半身数据稀缺的问题,EchoMimicV2创新性地引入了头部局部注意力机制。这一机制能够在训练过程中有效利用头部图像数据,提高模型的泛化能力和细节表现能力。同时,在推理阶段,这些数据可以被省略,从而降低了对输入数据的依赖,为动画生成提供了更大的灵活性。
3. 阶段特定去噪损失
为了进一步提升动画质量,EchoMimicV2设计了阶段特定的去噪损失函数。这些损失函数分别指导动画在不同阶段的运动、细节和低级质量表现,通过多层次的优化方法,使得生成的动画在整体效果和细节表现上都得到了显著提升。
4. 简化控制条件
与传统动画生成技术相比,EchoMimicV2在控制条件上进行了大幅简化。用户只需输入一张参考图像、一段手势视频和一段音频片段,即可生成新的数字人动画。这种简化的控制方式不仅降低了操作门槛,还提高了动画生成的效率和灵活性。
技术细节
EchoMimicV2在技术实现上采用了多种先进技术和算法,这些技术细节共同支撑起了其强大的动画生成能力。
1. 深度学习模型
EchoMimicV2基于深度学习框架构建,通过训练大规模的数据集来优化模型参数。模型采用了卷积神经网络(CNN)、循环神经网络(RNN)等多种神经网络结构,以捕捉音频、图像和视频中的复杂特征。同时,模型还引入了注意力机制、生成对抗网络(GAN)等先进技术,以提高生成动画的真实感和细节表现。
2. 音频特征提取
在音频处理方面,EchoMimicV2采用了先进的音频特征提取算法。这些算法能够捕捉音频中的语调、节奏、情感等多种信息,并将其转化为模型可理解的数值特征。这些特征随后被用于驱动动画角色的动作和表情生成。
3. 姿态估计与动作合成
为了生成自然的动画效果,EchoMimicV2还结合了姿态估计和动作合成技术。姿态估计算法能够识别输入视频中的手势和头部动作信息,并将其转化为模型可理解的姿态参数。动作合成算法则根据这些姿态参数和音频特征生成动画角色的动作序列和表情变化。
4. 渲染与优化
最后,EchoMimicV2还采用了先进的渲染技术和优化算法来提高动画的视觉效果和性能表现。渲染技术能够生成高质量的图像和视频输出,而优化算法则能够降低计算复杂度、提高生成速度并减少资源消耗。
应用场景
EchoMimicV2的广泛应用场景展示了其在不同领域的潜力和价值。
1. 娱乐产业
在娱乐产业中,EchoMimicV2可以用于生成虚拟偶像、动画角色和电影特效等。通过音频驱动技术,动画角色能够根据音频输入实时生成逼真的面部表情和手势动作,从而为观众带来更加生动、有趣的观看体验。
2. 教育培训
在教育培训领域,EchoMimicV2可以用于生成虚拟教师或培训师,帮助学生更好地理解和掌握学习内容。通过音频驱动技术,虚拟教师能够根据讲解内容实时生成相应的面部表情和手势动作,从而提高教学效果和学生的学习兴趣。
3. 医疗健康
在医疗健康领域,EchoMimicV2可以用于生成虚拟医生或护士,帮助患者更好地理解和配合治疗过程。通过音频驱动技术,虚拟医生能够根据诊疗内容实时生成相应的面部表情和手势动作,从而提高患者的治疗效果和满意度。
4. 商业广告
在商业广告领域,EchoMimicV2可以用于生成虚拟代言人或广告角色,帮助品牌更好地传达产品信息和品牌形象。通过音频驱动技术,虚拟代言人能够根据广告内容实时生成相应的面部表情和手势动作,从而提高广告效果和消费者的购买意愿。
相关链接
总结
EchoMimicV2作为一款先进的音频驱动半身人类动画生成模型,在功能特色、技术细节和应用场景等方面都展现出了显著的优势和潜力。通过音频姿势动态协调策略、头部局部注意力机制、阶段特定去噪损失等创新技术,EchoMimicV2能够生成高质量、逼真的半身人类动画效果。同时,其广泛的应用场景也为用户提供了多样化的选择和可能性。在未来,随着技术的不断发展和完善,EchoMimicV2有望在更多领域发挥重要作用并创造更大的价值。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2410.html


























