在数字时代,虚拟头像(Avatar)的应用日益广泛,涵盖了广告、视觉特效、虚拟现实等多个领域。然而,如何高效地生成高质量、可动画化的虚拟头像一直是技术界的一大挑战。近日,来自多伦多大学及向量研究所的研究团队发布了CAP4D模型,这一创新技术为虚拟头像的生成与动画化带来了革命性的突破。

CAP4D是什么
CAP4D是一种基于形变多视角扩散模型(MMDM)的新技术,旨在通过任意数量的参考图像生成逼真的4D(动态3D)头像。该模型采用双阶段方法,首先利用MMDM生成不同视角和表情的图像,然后将这些生成的图像与参考图像结合,重建出一个可实时控制的4D头像。CAP4D的发布标志着虚拟头像生成技术迈入了一个全新的阶段,为用户提供了前所未有的灵活性和逼真度。
功能特色
任意数量的参考图像
CAP4D模型的最大特色之一在于它能够处理任意数量的参考图像。无论是单张图像、少量图像还是多达数百张的图像,CAP4D都能够高效地生成高质量的4D头像。这一功能极大地拓宽了虚拟头像的应用场景,使得用户可以根据实际需求灵活选择参考图像的数量。
逼真的4D头像生成
通过采用双阶段方法,CAP4D模型能够生成逼真的4D头像。首先,MMDM生成不同视角和表情的图像;其次,将这些生成的图像与参考图像结合,重建出一个可实时控制的4D头像。这一过程中,CAP4D模型充分考虑了头部姿态、表情及摄像机视角等信息,从而确保了生成的4D头像在视觉上的逼真度。
实时动画与渲染
CAP4D模型不仅具备生成高质量4D头像的能力,还能够实现实时动画与渲染。通过与现有图像编辑模型相结合,用户可以对生成的头像进行外观和光照的编辑。此外,CAP4D还能将生成的4D头像与语音驱动动画模型结合,实现音频驱动的动画效果。这使得头像不仅能够展现静态的视觉效果,还能通过声音与用户进行动态互动。

技术细节
形变多视角扩散模型(MMDM)
MMDM是CAP4D模型的核心技术之一。它是一种基于扩散模型的方法,能够生成不同视角和表情的图像。MMDM通过随机采样的方式,在每一步迭代生成过程中结合输入的参考图像生成多个不同的图像。这一技术使得CAP4D模型能够处理任意数量的参考图像,并生成高质量的4D头像。
变分自编码器与3D形变模型
在CAP4D的工作流程中,用户输入的参考图像将被编码到变分自编码器的潜在空间中。接着,使用现成的面部追踪技术FlowFace估计每张参考图像的3D形变模型(FLAME)。FLAME模型能够提取出头部姿态、表情及摄像机视角等信息,这些信息对于生成逼真的4D头像至关重要。
随机输入/输出条件程序
为了克服MMDM在支持有限数量的参考和生成图像方面的限制,CAP4D模型采用了一种随机输入/输出条件程序。这一程序使得CAP4D能够基于大量参考图像生成数百个新视角。通过随机采样和条件约束,CAP4D模型能够在保持视觉一致性的同时,生成多样化的4D头像。
与现有图像编辑模型结合
CAP4D模型还具备与现有图像编辑模型相结合的能力。这使得用户可以对生成的4D头像进行外观和光照的编辑,从而进一步提升头像的逼真度和表现力。例如,用户可以通过调整光照条件和纹理细节来优化头像的外观效果。
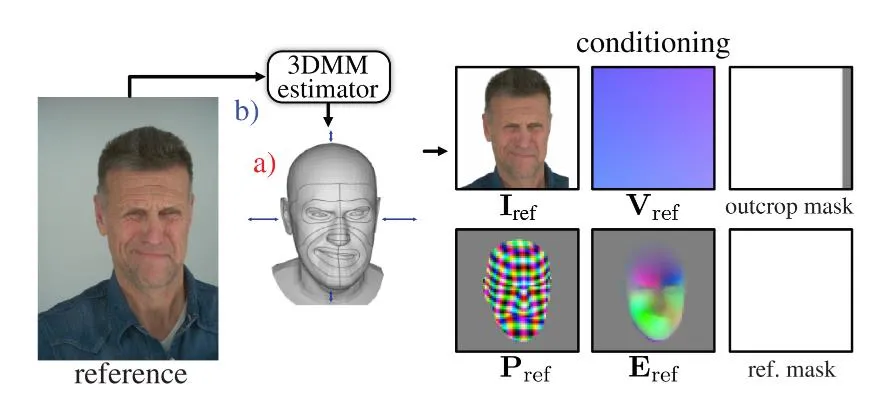
应用场景
广告与营销
在广告与营销领域,CAP4D模型可以生成逼真的4D头像作为品牌代言人或产品展示。通过实时动画与渲染技术,这些4D头像能够与观众进行动态互动,提升广告的吸引力和参与度。
视觉特效与动画制作
在视觉特效与动画制作领域,CAP4D模型可以生成高质量的4D头像作为角色模型。这些角色模型不仅具备逼真的外观和动作效果,还能够通过音频驱动实现动态互动。这使得动画制作者能够更加灵活地创作出生动有趣的角色形象。
虚拟现实与游戏开发
在虚拟现实与游戏开发领域,CAP4D模型可以生成玩家的个性化4D头像。这些头像不仅能够展现玩家的独特外观和表情特征,还能够通过音频驱动实现动态互动。这极大地增强了虚拟现实和游戏世界的沉浸感和互动性。
社交媒体与在线交流
在社交媒体与在线交流领域,CAP4D模型可以生成用户的个性化4D头像作为虚拟形象。这些虚拟形象不仅具备逼真的外观和动作效果,还能够通过音频驱动实现动态互动。这使得用户能够在社交媒体平台上以更加生动有趣的方式展示自己并与他人交流。
总结
CAP4D模型作为一种基于形变多视角扩散模型的新技术,在虚拟头像生成与动画化方面展现了巨大的潜力和价值。通过任意数量的参考图像生成逼真的4D头像、实现实时动画与渲染以及结合现有图像编辑模型进行外观和光照编辑等功能特色,CAP4D模型为广告、视觉特效、虚拟现实等多个领域带来了革命性的突破。随着技术的不断发展和完善,相信CAP4D模型将在未来发挥更加重要的作用,为用户创造更加丰富、逼真的虚拟头像体验。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2771.html


























