随着人工智能技术的快速发展,多模态大语言模型(Multimodal Large Language Models, MLLMs)逐渐成为推动人机交互与行业智能化升级的核心驱动力。在这一背景下,R1-Omni作为一款全能型多模态语言模型,凭借其强大的跨模态理解能力与灵活的适应性,正在重新定义通用人工智能的边界。
一、R1-Omni概述
R1-Omni是阿里通义团队研发并开源的全模态大语言模型,它采用了强化学习中的RLVR(Reinforcement Learning with Verifiable Reward)训练范式,并结合了GRPO(Generative Relative Policy Optimization)方法,实现了对视觉和音频信息的深度整合和高效利用。R1-Omni专注于情感识别任务,能够同时处理视频和音频内容,提供可解释的推理过程,并显著提升了情感识别的准确性和泛化能力。
二、功能特色
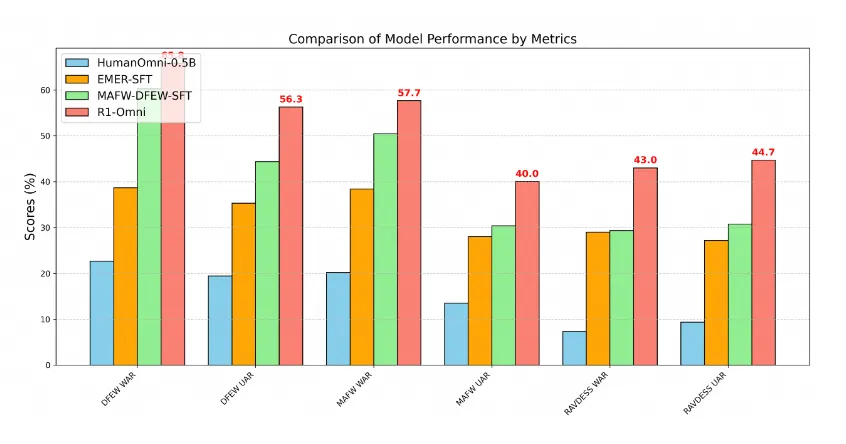
穿透式情感分析:R1-Omni能够结合视觉微表情和语音语调进行情感分析,识别准确率远超传统模型。这一特性使得R1-Omni在情感计算领域具有独特的优势,能够更准确地捕捉和理解人类的情感变化。
白盒级推理解释:R1-Omni提供了透明的决策逻辑,能够生成详细的推理过程,解释模型是如何整合视觉和音频线索得出预测的。这一特性增强了模型的可解释性,使得R1-Omni在情感计算领域的应用更加广泛和可靠。
工业级泛化能力:R1-Omni在多个情感识别数据集上表现出色,具有很强的泛化能力。无论是在同分布测试集还是在不同分布测试集上,R1-Omni都展现了卓越的性能。这一特性使得R1-Omni能够更好地适应未见场景,为情感计算的应用提供了更广阔的空间。
三、技术细节
RLVR训练范式:RLVR是R1-Omni的核心训练范式,它基于验证函数直接评估模型输出,无需依赖传统的人类反馈强化学习(RLHF)中的单独奖励模型。给定输入问题q,策略模型πθ生成响应o,然后使用可验证奖励函数R(q,o)对其进行评估,优化目标是最大化验证奖励减去基于KL散度的正则化项。RLVR简化了奖励机制,同时确保了与任务内在正确性标准的一致性。
GRPO方法:GRPO是R1-Omni采用的另一种关键技术,它避免了使用额外的评论家模型,直接比较生成的响应组,增强了模型区分高质量和低质量输出的能力。具体过程是:针对一个问题q,采样多组输出{o1, o2, …, oG},对每个输出计算奖励分{r1, r2, …, rG},然后对这些奖励分进行归一化处理,形成相对奖励。GRPO能够更直接地反映同一问题下不同输出的优劣关系,从而优化模型性能。
冷启动策略:R1-Omni的模型构建采用了受DeepSeek-R1启发的冷启动策略。首先,在包含232个可解释多模态情感推理数据集(EMER)样本和348个手动标注的HumanOmni数据集样本的组合数据集上,对HumanOmni-0.5B进行微调。这一步骤使模型具备初步的推理能力,了解视觉和音频线索是如何对情感识别产生作用的。之后,通过RLVR训练进一步优化模型。
奖励函数设计:在RLVR训练过程中,奖励函数由两部分组成:准确率奖励和格式奖励。准确率奖励用于评估预测情感与真实情感的匹配度,格式奖励确保模型输出符合指定的HTML标签格式。这一设计保证了情感识别的准确性和输出的可解释性。
四、应用场景
客服领域:R1-Omni能够实时分析客户的情感变化,为客服人员提供准确的情感反馈,帮助他们更好地理解和回应客户的需求,提升客户满意度。
影视行业:R1-Omni可以批量分析观众在观看影视作品时的情感变化,为影视制作方提供有价值的观众反馈,帮助他们优化剧情和角色设定,提升影视作品的质量。
心理测评:R1-Omni能够准确识别和分析个体的情感状态,为心理咨询师提供客观的情感数据支持,帮助他们更准确地评估个体的心理状态,制定更有效的心理咨询方案。
五、相关链接
GitHub仓库:https://github.com/HumanMLLM/R1-Omni
六、总结
R1-Omni作为阿里通义团队开源的全模态大语言模型,在情感计算领域展现出了卓越的性能和广泛的应用前景。它采用RLVR训练范式和GRPO方法,实现了对视觉和音频信息的深度整合和高效利用,提供了透明的决策逻辑和详细的推理过程,显著提升了情感识别的准确性和泛化能力。同时,R1-Omni还具有丰富的应用场景和便捷的官方资源支持,为用户提供了全面的解决方案。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3510.html


























