
一、AccVideo是什么
AccVideo是由北京航空航天大学、上海人工智能实验室和香港大学联合研发的一项技术,旨在通过合成数据集加速视频扩散模型的推理过程。AccVideo的核心思想是利用预训练的视频扩散模型生成多个有效的去噪轨迹作为合成数据集,从而避免了蒸馏过程中无用数据点的使用。基于这些合成数据集,AccVideo设计了一种基于轨迹的少步指导方法,利用关键数据点学习噪声到视频的映射关系,从而在更少的步骤内完成视频生成。
相比传统的视频生成方法,AccVideo能够显著减少推理步骤,提升生成速度。实验结果表明,AccVideo相较于教师模型提升了8.5倍的生成速度,同时保持了相似的性能表现。此外,AccVideo还引入了对抗训练策略,以对齐学生模型与合成数据集之间的输出分布,进一步提高了生成视频的质量和分辨率。这种技术创新不仅为视频生成领域带来了新的可能性,也为大规模应用提供了更高的效率和更低的成本。
二、功能特色
1. 高效性
AccVideo的最大特色在于其高效性。与现有的方法相比,AccVideo实现了8.5倍的速度提升,同时保持了与教师模型相当的性能水平。这意味着用户可以在更短的时间内生成高质量的视频内容,极大地提高了生产效率。
2. 高质量视频生成
AccVideo不仅能加速视频生成过程,还能生成更高质量和分辨率的视频。例如,它可以生成长达5秒、分辨率为720x1280、帧率为24fps的视频,这些视频具有丰富的细节和生动的画面效果。
3. 创新性的技术方法
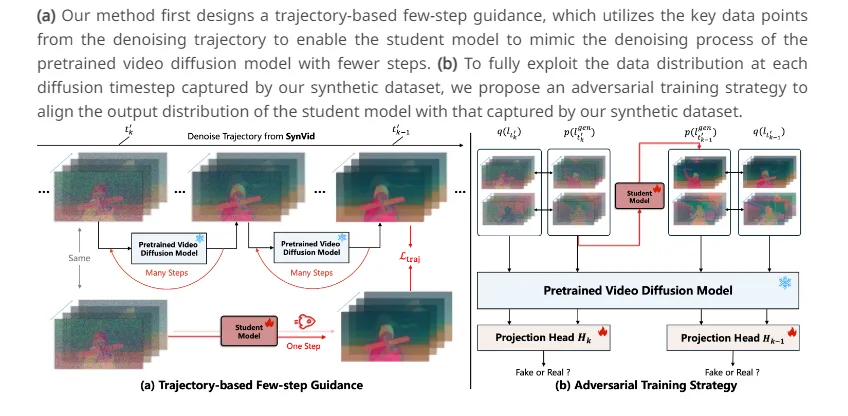
AccVideo采用了基于轨迹的少量步骤指导策略,利用去噪轨迹中的关键数据点来学习噪声到视频的映射关系。这种方法使得学生模型能够在较少的步骤中模仿预训练视频扩散模型的去噪过程。
三、技术细节
1. 合成数据集的构建
AccVideo的核心之一是合成数据集的构建。该方法利用预训练的视频扩散模型生成多个有效的去噪轨迹作为合成数据集。这种做法有效地避免了在蒸馏过程中使用无用的数据点,从而提高了数据的有效性和模型的训练效率。
2. 轨迹基础的少量步骤指导
为了充分利用合成数据集中捕捉到的数据分布,AccVideo设计了一种基于轨迹的少量步骤指导策略。这一策略选取去噪轨迹中的关键数据点,用于学习从噪声到视频的映射关系,使视频可以在较少的步骤中生成。
3. 对抗性训练策略
由于合成数据集捕获了每个扩散时间步的数据分布,AccVideo引入了一种对抗性训练策略。该策略旨在将学生模型的输出分布与合成数据集所捕获的分布对齐,从而增强视频的质量。
四、应用场景
1. 视频内容创作
AccVideo可以广泛应用于视频内容创作领域,帮助创作者快速生成高质量的视频内容。无论是广告宣传视频还是教育视频,AccVideo都能提供快速且高效的解决方案。
2. 实时视频处理
在实时视频处理方面,AccVideo的表现同样出色。例如,在直播平台或视频会议系统中,AccVideo可以帮助实现更快的视频处理速度,提升用户体验。
3. 增强现实(AR)和虚拟现实(VR)
在AR和VR领域,AccVideo可以通过快速生成高质量的视频内容,增强用户的沉浸感和交互体验。这对于游戏开发、虚拟旅游等应用具有重要意义。
五、相关链接
论文链接:https://arxiv.org/abs/2503.19462
GitHub项目页:https://github.com/aejion/AccVideo/
项目主页:https://aejion.github.io/accvideo/
六、总结
AccVideo作为一种新型的视频扩散模型加速方法,通过合成数据集和创新的技术手段,成功地解决了传统扩散模型中存在的效率低下问题。它不仅提升了视频生成的速度,还保证了视频的质量和分辨率。无论是在视频内容创作、实时视频处理还是AR/VR领域,AccVideo都有着广泛的应用前景。未来,随着技术的不断发展和完善,AccVideo有望成为视频生成领域的标准工具,为更多用户提供高效、高质量的服务。
总之,AccVideo以其独特的技术和卓越的性能,正在重新定义视频生成的可能性。对于希望提升视频生成效率的开发者和创作者来说,AccVideo无疑是一个值得探索和应用的强大工具。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3667.html


























