随着人工智能技术的飞速发展,视频生成领域正迎来前所未有的变革。MAGI-1(Massive Autoregressive Generation of Imagery),作为Sand-AI团队推出的一款革命性开源模型,以其强大的功能和创新的技术架构在视频生成领域脱颖而出。

MAGI-1是什么?
MAGI-1是一款基于自回归算法的大规模视频生成模型,旨在通过预测一系列视频块(chunks)来生成高质量视频。它能够根据文本指令或图像输入生成连贯且逼真的视频内容,同时支持实时部署和灵活控制。MAGI-1不仅在图像到视频(I2V)、文本到视频(T2V)等任务中表现出色,还通过物理行为预测展现了卓越的时间一致性与高精度。
这款模型的发布标志着视频生成技术从实验阶段迈向了实用化的新高度,为创作者提供了全新的工具,也为学术研究开辟了新的方向。
功能特色
1. 自回归视频生成
MAGI-1采用自回归方式生成视频,即将视频划分为固定长度的块(chunk),每块包含24帧连续画面。通过对每个块逐步去噪并串联生成最终视频,这种方法显著提高了生成效率和时间连贯性。
2. 高时间一致性
得益于自回归架构的优势,MAGI-1在生成过程中保持了极高的时间一致性,尤其在需要长时间序列合成的任务中表现突出。例如,在物理行为预测基准测试中,MAGI-1超越了现有所有模型,展现出非凡的能力。
3. 可控生成
用户可以通过分块提示(chunk-wise prompting)实现对生成过程的精细控制,包括平滑场景转换、长时域合成以及基于文本驱动的细节调整。这种灵活性使得MAGI-1适用于多种复杂场景。
4. 高效解码与重建质量
MAGI-1结合了变分自编码器(VAE)和Transformer架构,实现了8倍空间压缩和4倍时间压缩,从而大幅提升了解码速度,同时保持了极具竞争力的重建质量。
5. 多步推理优化
通过引入“自我一致性约束”(self-consistency constraint),MAGI-1能够在不同步数之间近似匹配轨迹,从而支持可变推理预算。这一特性允许用户根据硬件性能选择合适的推理步骤,而不会显著牺牲生成质量。
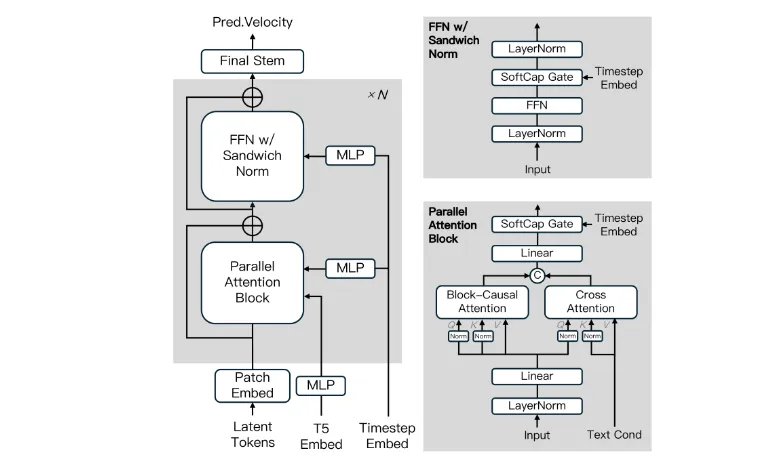
技术细节
1. 核心架构
MAGI-1基于扩散变换器(Diffusion Transformer)构建,融合了多项技术创新以提升训练效率和稳定性:
Block-Causal Attention:增强因果关系建模能力。
Parallel Attention Block:加速注意力计算。
QK-Norm 和 GQA:改进注意力机制的数值稳定性。
Sandwich Normalization in FFN:优化前馈网络中的归一化操作。
SwiGLU 和 Softcap Modulation:提高非线性表达能力。
这些设计共同作用,使MAGI-1能够在大规模数据集上高效训练,同时保证生成结果的质量。
2. 自回归去噪算法
MAGI-1使用自回归去噪算法逐块生成视频。具体来说,它通过增加单调噪声来训练模型,并在生成阶段逐步减少噪声,直到获得清晰的视频块。这种方法自然支持流式生成,非常适合在线应用。
3. 分布式训练与蒸馏
为了降低推理成本,MAGI-1采用了短路蒸馏(shortcut distillation)方法,训练单一速度模型以适应不同的推理预算。此外,通过循环采样步长大小(如{64, 32, 16, 8}),模型可以学习在多种步长下逼近流动匹配轨迹。
4. 模型权重与版本
目前,MAGI-1提供了两个主要版本的预训练权重:
24B参数模型:适用于高性能服务器环境。
4.5B参数模型:适合资源受限设备。 此外,还有经过蒸馏和量化处理的轻量级版本可供选择。
应用场景
1. 创意内容生产
MAGI-1可以帮助艺术家、设计师快速生成符合特定主题的动态视觉内容。无论是制作短片、广告还是动画,用户只需提供简单的文本描述或参考图片即可完成创作。
2. 虚拟现实与增强现实
凭借强大的实时生成能力和精确的物理行为预测,MAGI-1可广泛应用于VR/AR环境中,为用户提供沉浸式体验。
3. 教育与科研
在教育领域,MAGI-1可用于制作教学视频;在科学研究中,则能辅助模拟复杂动态系统的行为,例如天气变化或分子运动。
4. 游戏开发
游戏开发者可以利用MAGI-1生成动态过场动画或NPC互动场景,从而减少手动设计的工作量。
5. 工业仿真
MAGI-1的高时间一致性和物理行为预测能力使其成为工业仿真的理想工具,可用于机器人路径规划、产品装配流程优化等领域。
相关链接
总结
MAGI-1作为一款开创性的视频生成模型,以其独特的自回归架构、高效的去噪算法和灵活的可控生成能力重新定义了视频生成的可能性。无论是在创意内容生产、虚拟现实还是科学研究等领域,MAGI-1都展现出了巨大的潜力和价值。未来,随着更多研究人员和技术爱好者的加入,相信MAGI-1将在视频生成领域掀起新一轮的技术浪潮。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3953.html


























