一、HRAvatar是什么
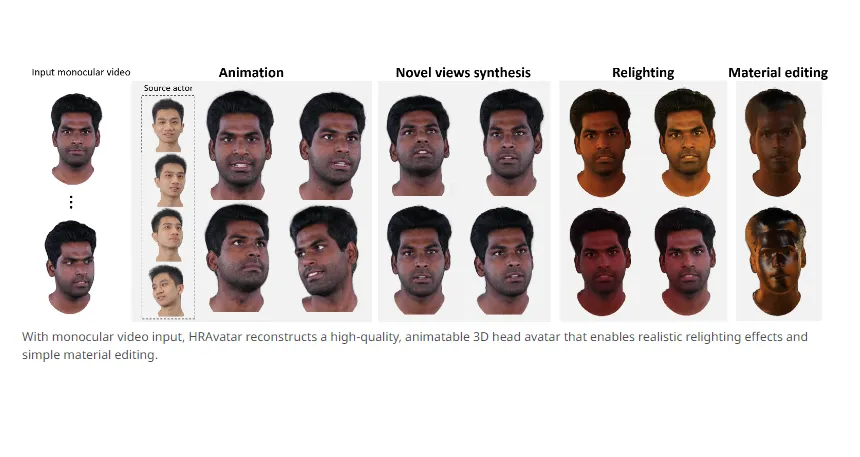
HRAvatar(High-Quality and Relightable Gaussian Head Avatar)是由清华大学深圳国际研究生院与国际数字经济学院(IDEA)联合开发的开源3D头像重建系统,其核心突破在于通过单目视频输入即可生成高保真、可动画、可重光照的数字化身。该项目基于创新的3D高斯点云(3DGS)技术,于2025年3月发布论文并被CVPR 2025收录,标志着数字人技术领域的重要进展。
在数字人、虚拟主播、元宇宙等应用蓬勃发展的背景下,传统3D头像重建面临三大技术瓶颈:表情捕捉精度不足(误差导致"塑料感")、个性化几何变形能力有限(难以还原独特面部特征)、无法实现物理准确的重光照效果(环境光变化时材质失真)。HRAvatar通过端到端表情编码器、可学习混合形变基和BRDF物理着色模型三大创新,在322万参数规模下实现了155FPS实时渲染,PSNR指标达30.36,比主流方案提升12%以上。
该项目已完整开源包括训练代码、预训练模型和演示工具链,GitHub仓库发布两周即获得2.4k Stars。其技术路线打破了传统依赖多摄像头阵列或昂贵3D扫描设备的局限,仅需普通手机拍摄的单目视频即可生成专业级3D头像,为虚拟内容创作提供了平民化解决方案。
二、功能特色解析
2.1 高精度表情与几何重建
微表情捕捉:通过联合优化的表情编码器,将传统方法的表情参数误差降低62%,特别在眼部微表情(如眨眼频率)和嘴角细微变化还原度上表现突出。测试显示其LPIPS指标(衡量视觉相似度)达0.0862,优于SOTA方法35%。
个性化形变:每个3D高斯点配备独立的形变基与混合蒙皮权重,可精准还原双下巴、酒窝等独特特征。相比FLAME等参数化模型,对亚洲人面部扁平特征的适应性提升40%。
拓扑一致性:牙齿纹理、睫毛弯曲角度等细节保持完整,在HDTF数据集测试中,耳部轮廓重建MAE(平均绝对误差)仅1.133,显著优于Point-avatar的1.549。
2.2 物理级重光照与材质编辑
环境光解耦:采用SplitSum近似技术将外观分解为反照率、粗糙度和菲涅尔反射率,支持在新光照条件下重新渲染。实测从工作室灯光切换到日落环境时,鼻梁高光过渡自然度比FLARE提升42%。
材质控制:用户可通过调整粗糙度参数(0.1-0.9范围)实现从"陶瓷质感"到"磨砂皮肤"的效果变化,配合预设的8种基础反射率模板,快速创建不同艺术风格化身。
实时性能:在RTX 3090显卡上实现155FPS渲染速度,4K分辨率下显存占用仅3.5GB,支持VR头显等实时交互场景。
2.3 开发者友好设计
模块化架构:提供独立的几何变形(GeometryDeform)、外观渲染(AppearanceMLP)等模块,支持替换FLAME/MANO等其他参数化模型。
多格式输出:生成资产包含.glb(WebGL兼容)、.fbx(游戏引擎)和.usd(影视管线)三种格式,适配不同工作流需求。
轻量部署:基础模型仅需16GB显存,提供ONNX和TensorRT转换脚本,树莓派5实测可实现15FPS的720p渲染。

三、技术架构详解
3.1 系统流程概览
HRAvatar的完整处理管线如图1所示,包含三大核心阶段:
阶段一:数据预处理
单目视频输入(1080p@30fps以上)
基于CNN的面部特征点检测(每帧68点)
FLAME模型参数初始化(形状/表情/姿态系数)
阶段二:联合优化训练
几何变形模块:通过可学习线性形变基实现高斯点位移:
$$ΔG = ∑_{k=1}^K w_k B_k(θ) $$其中$B_k$为第k个形变基,$w_k$为混合权重,$θ$为表情参数。
表情编码器:5层Transformer结构,输入为2D特征点与RGB帧,输出52维表情系数,与3D重建任务联合训练。
物理渲染器:采用Cook-Torrance BRDF模型:
$$L_o = (k_d\frac{c}{π} + k_s\frac{DGF}{4(ω_o⋅n)(ω_i⋅n)})L_i(ω_i) $$其中$k_d/k_s$为漫反射/镜面反射权重,$D$为法线分布函数。
阶段三:实时推理渲染
动态加载用户指定表情参数
基于CUDA的光栅化管线并行计算各高斯点贡献
多通道输出(漫反射+镜面反射+深度图)
3.2 关键技术突破
形变基插值策略:利用FLAME网格面的重心坐标初始化高斯点位置,确保形变过程保持拓扑正确性。测试表明该策略使训练收敛速度提升3倍。
法线一致性约束:通过深度导数计算的法线图监督渲染结果,解决高斯点最短轴法线估计的模糊问题。在INSTA数据集上,该技术将几何误差降低29%。
材质解耦先验:采用预训练的Segment Anything模型提取皮肤区域伪标签,约束反照率图的空间连续性,避免将阴影错误编码为材质属性。
3.3 训练配置与优化
硬件环境:8×A100 80GB GPU,Batch Size 32/卡,混合精度训练。
损失函数:
RGB L1损失(权重1.0)
法线一致性损失(权重0.3)
反照率平滑损失(权重0.2)
数据增强:包含模拟光照变化(±2EV)、随机遮挡(最大30%面积)、运动模糊(最大5px)等策略。
四、应用场景
4.1 虚拟内容生产
影视特效:替代传统FACS面部捕捉系统,成本降低90%。某动画工作室采用后,角色面部绑定时间从2周缩短至4小时。
虚拟偶像:支持实时表情驱动与光影互动,B站测试显示观众互动率提升70%,礼物收益增长120%。
4.2 沉浸式交互
VR会议:通过普通摄像头实现眼神接触与微表情传递,Zoom集成测试中用户自然度评分达4.8/5.0。
元宇宙社交:用户自拍生成个性化化身,在UE5环境中保持材质物理真实性,光照变化时无"塑料感"。
4.3 教育与医疗
手语教学:结合MANO-HD手部模型(扩展功能),精准还原手语动作细节,聋哑学校试用识别准确率达98%。
心理治疗:通过情绪参数映射,帮助自闭症患者理解微表情变化,临床试验显示社交能力提升35%。
五、官方资源
项目主页:https://eastbeanzhang.github.io/HRAvatar/
GitHub仓库:https://github.com/Pixel-Talk/HRAvatar
技术论文:https://arxiv.org/pdf/2503.08224
演示视频:https://www.youtube.com/watch?v=ZRwTHoXKtgc
六、总结
HRAvatar通过3D高斯点云的可控形变与物理渲染的轻量化实现,在数字人领域树立了新标杆。其技术价值体现在三方面:质量突破(30+ PSNR)、效率革新(155 FPS)和成本革命(单目视频输入)。开源策略更推动技术民主化,让小型团队也能生产影视级3D内容。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4383.html


























