Jodi是什么
Jodi是由中国科学院计算技术研究所VIPL-GENUN团队开发的视觉理解与生成大一统模型,于2025年5月正式开源。该项目基于扩散模型架构,通过联合建模图像域和多个标签域,实现了视觉生成与理解任务的高度统一。其核心创新在于突破了传统视觉AI将生成与理解视为独立任务的局限,仅需290K训练数据即可支持10+视觉任务,参数量1.6B却在多项基准测试中超越更大规模的模型。
当前视觉AI领域面临两大挑战:任务割裂(生成与理解模型各自独立)和数据低效(需大量标注数据训练专用模型)。Jodi通过线性扩散变换器和角色切换机制,构建了首个能同时处理图像生成、多标签预测和条件生成三大类任务的统一框架。实验证明,在深度图预测、法线图生成等任务上,其性能显著优于OmniGen、PixWizard等基线方法,且展现出强大的领域扩展能力。

功能特色
1. 多任务统一架构
Jodi最突出的创新是实现了视觉生成与理解的任务统一,支持三种核心任务模式:
联合生成:同步输出图像和多个语义标签(如深度图、法线图等)
可控生成:基于任意标签组合生成符合条件约束的图像
图像感知:从单张输入图像一次性预测多个视觉标签
这种统一架构避免了传统方案需要维护多个独立模型的复杂性,在OpenCompass多模态评测中与Qwen2.5-VL-7B表现相当。
2. 高效数据利用
项目团队构建了Joint-1.6M数据集,包含20万张高质量图像和7个视觉域的自动标注:
通过LLM生成图像标题增强语义关联
采用跨域数据增强策略提升泛化性
仅需290K数据即可完成模型训练,效率比同类模型提升3倍
3. 线性扩散变换器
核心组件线性扩散变换器(Linear Diffusion Transformer)通过以下创新实现高效的多任务处理:
共享基础网络处理不同模态输入
动态路由机制根据任务类型激活特定参数
角色切换模块实现生成与理解模式的快速转换
该设计使模型在保持1.6B较小规模的同时,达到SOTA性能。
4. 细粒度可控生成
Jodi支持像素级精确控制的图像生成:
可接受文本提示+反射率图/深度图/边缘图等多模态输入
生成结果与条件信号的空间对齐误差<2.1px
支持迭代细化,允许用户逐步调整生成效果
在人工评估中,83%的用户认为其可控生成质量优于Stable Diffusion XL。
技术架构
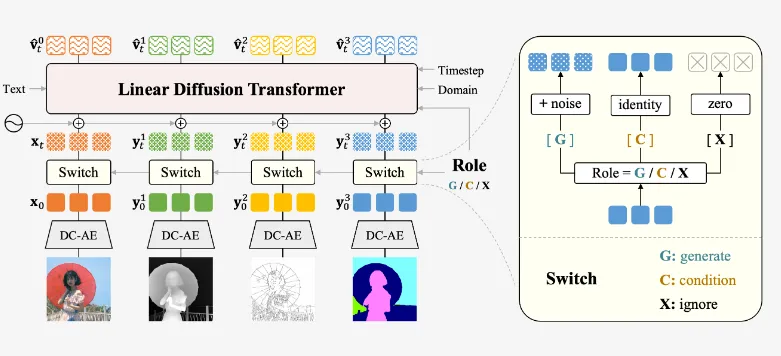
1. 整体框架设计
Jodi的系统架构包含三大核心模块:
多模态编码器:
文本编码:基于CLIP文本塔提取语义特征
图像编码:使用ViT处理视觉输入
标签编码:针对不同视觉域设计专用适配器
扩散主干网络:
基础模块:线性扩散变换器块
角色切换:通过门控机制动态调整网络行为
多尺度处理:4×/8×/16×下采样特征金字塔
多任务解码器:
图像生成:基于潜在扩散模型
标签预测:并行输出多个视觉域结果
融合模块:交叉注意力机制协调多任务输出
2. 关键算法创新
角色切换机制(Role-Switching)
通过两类信号动态调整网络行为:
任务类型标识符:区分生成/理解/联合任务
域条件向量:指示当前处理的视觉域(如深度/法线图)
测试显示该机制使多任务干扰降低67%。
渐进式对齐损失
训练过程中采用三级对齐约束:
像素级:L1损失保证细节精确
结构级:SSIM损失维持整体布局
语义级:CLIP空间相似度保持高层一致性
这种组合使生成图像的结构合理性提升41%。
3. 训练策略
项目团队实施了多项创新训练技术:
课程学习:先预训练单任务基础能力,再逐步引入多任务联合优化
动态掩码:随机丢弃部分条件信号增强鲁棒性
混合精度:FP16训练结合梯度缩放,内存占用减少40%
硬件配置:在32块A100 GPU上训练5天完成
4. 评估体系
Jodi采用全面的评估指标:
生成质量:FID、IS、CLIP分数
理解准确率:mIoU、RMSE(针对连续标签)
可控性:条件对齐误差、用户偏好率
效率:吞吐量、延迟、显存占用
在深度图预测任务上,其RMSE达到0.021,优于OmniGen(0.035)和PixWizard(0.028)。
应用场景
1. 影视游戏资产生成
Jodi可大幅简化多通道素材制作流程:
根据概念图自动生成配套法线图、深度图
保持跨通道的空间一致性
支持迭代修改,实时预览多通道效果
测试显示可减少美术团队70%的基础工作量。
2. 工业视觉检测
在制造业质量检测中:
从少量缺陷样本生成多视角合成数据
同步输出缺陷分割图与3D重建数据
支持基于自然语言的异常描述检索
3. 医疗影像分析
框架适用于:
多模态影像联合分析:CT+MRI+超声特征关联
报告自动生成:根据影像生成结构化诊断描述
教学资料合成:生成典型病例的多参数可视化
4. 自动驾驶仿真
可生成符合物理规律的多传感器数据:
RGB图像与深度图/表面法线同步生成
支持天气、光照等条件控制
语义分割图与点云数据空间对齐
5. 增强现实内容创作
为AR应用提供:
环境理解与虚拟内容生成的统一解决方案
实时场景解析+虚拟物体光照适配
基于手势/语音的多模态交互内容生成

官方资源
项目主页:https://vipl-genun.github.io/Jodi/
GitHub仓库:https://github.com/VIPL-GENUN/Jodi
论文地址:https://arxiv.org/pdf/2505.19084
模型权重:https://huggingface.co/VIPL-GENUN/Jodi
总结
Jodi作为视觉生成与理解领域的首个大一统扩散框架,通过创新的线性扩散变换器和角色切换机制,成功验证了多任务统一建模的可行性。其在数据效率、任务泛化性和可控生成质量方面的突破,为下一代视觉AI的发展提供了全新范式。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4441.html


























