一、4D-LRM是什么?
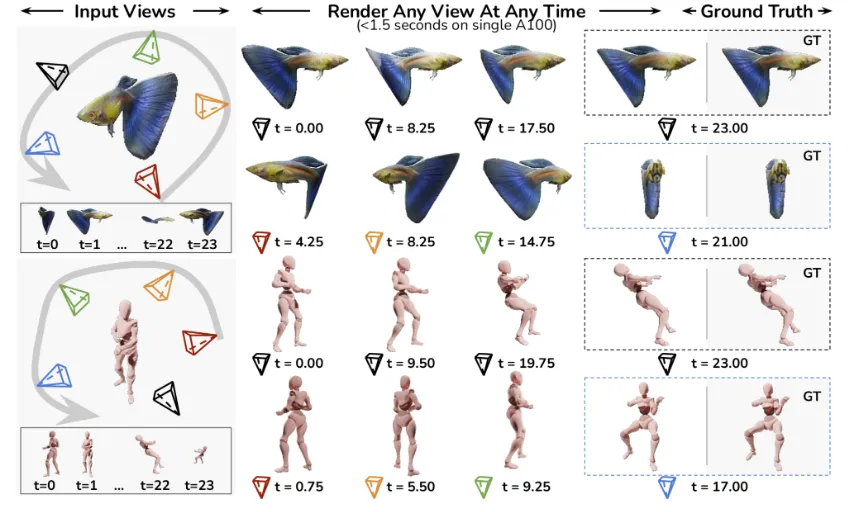
4D-LRM(Large Space-Time Reconstruction Model)是由Adobe Research联合密歇根大学、北卡罗来纳大学教堂山分校等机构开发的开源项目,旨在通过人工智能技术实现从稀疏视角输入重建完整4D动态场景的突破性能力。这里的“4D”指三维空间(3D)加时间维度(T),模型能够从少量多角度、多时刻的2D图像中,还原物体或场景的三维形状及其随时间变化的运动状态,并支持从任意视角和任意时间点生成高保真动态渲染结果。
与传统3D重建技术(如NeRF、3D高斯泼溅)仅能处理静态场景不同,4D-LRM首次将时空统一表示学习引入动态重建领域。其核心创新在于采用“4D高斯基元”(4D Gaussian primitives)作为基本表示单元,通过Transformer架构直接预测这些基元的时空参数,实现端到端的动态场景建模。
二、功能特色
1. 任意视角与任意时刻的动态重建
4D-LRM的核心功能是从稀疏输入(如几张不同角度、不同时间的照片)生成完整的4D场景。用户可通过指定时间戳和视角方向,实时渲染出物体在该时刻的状态,例如观察一个旋转中的汽车模型在特定角度的瞬间姿态。这一功能突破了传统动态重建技术对密集视频输入的依赖,仅需少量快照即可还原连续运动。
2. 少样本学习与高效泛化
模型通过在大规模4D数据集(含32,000个动态物体和783,000个静态物体转换的时序数据)上的预训练,具备强大的少样本生成能力。实验表明,仅需3-5张输入图像即可完成高质量重建,且对快速运动、复杂光照等场景具有鲁棒性。这一特性使其在数据获取成本高的领域(如影视特效、工业仿真)具有显著优势。
3. 实时推理与高保真渲染
4D-LRM在单块A100 GPU上仅需1.5秒即可完成24帧动态序列的重建,并支持256×256分辨率的实时渲染。其渲染质量在Consistent4D数据集上达到PSNR>30,显著优于传统逐帧3D重建方法。模型采用可微分渲染管线,通过4D高斯基元的叠加合成最终图像,兼顾了效率与视觉效果。
4. 时空插值与运动补全
当输入的时间序列存在缺失时,模型能自动学习时空插值策略:通过调整高斯基元的时间方差参数,将基元重新分配到缺失时间区域,实现运动轨迹的自然补全。例如,若输入仅包含物体运动的起始和结束状态,4D-LRM可生成中间过程的平滑过渡。
三、技术细节
1. 4D高斯基元表示
4D-LRM的基本构建单元是参数化的4D高斯基元,每个基元包含20个参数:
外观属性:RGB颜色(3通道)、透明度(1通道)
时空几何:中心坐标(3D空间+1D时间)、尺度参数(4D)、旋转四元数(8D)
动态特性:时间方差参数(控制基元在时间维度的影响范围)
这种表示方法将空间和时间统一建模,每个基元如同一个“时空胶囊”,记录局部区域的动态变化。相比传统体素(Voxel)或点云(Point Cloud),4D高斯基元具有更高的存储效率和渲染质量。
2. 模型架构
4D-LRM采用基于Transformer的编码器-解码器架构:
输入处理:多视角图像通过ResNet提取特征,转换为包含时间信息的“图像令牌”(Image Tokens)
时空编码:通过交叉注意力机制融合多视角、多时刻的令牌,生成全局时空上下文
4D高斯预测:解码器直接预测场景中所有4D高斯基元的参数,采用“像素对齐高斯”设计——每个输入像素对应一个基元,同时引入可选的“自由高斯令牌”以补充未被覆盖的时空区域
可微渲染:使用类似3D高斯泼溅(3DGS)的渲染器,通过叠加高斯核生成最终图像,支持端到端训练
3. 训练策略
项目采用两阶段课程学习:
预训练阶段:在128×128分辨率下训练10万步,使用Objaverse数据集(动态物体+静态物体转换的24帧序列)
微调阶段:在256×256分辨率下训练2万步,优化细节表现
训练硬件为160块A100 GPU,损失函数结合了RGB重建损失、时空一致性损失和基元分布正则化项。
四、应用场景
1. 虚拟现实与增强现实(VR/AR)
4D-LRM可生成沉浸式动态场景,用户通过VR设备可从任意角度观察虚拟物体的实时运动,例如交互式产品展示或虚拟博物馆中的动态文物。在AR领域,该技术能将真实场景中的动态物体(如运动中的运动员)实时重建并叠加到虚拟环境中。
2. 影视特效与动画制作
传统特效制作需逐帧手工建模或依赖昂贵的光学捕捉系统。4D-LRM允许导演从少量实拍素材重建完整动态场景,并自由调整视角和时间轴,大幅降低制作成本。例如,仅需演员的几段表演片段即可生成360度环绕拍摄效果。
3. 工业仿真与自动驾驶
在汽车制造领域,4D-LRM可模拟碰撞测试中车辆的形变过程;在机器人训练中,它能构建包含动态障碍物的虚拟环境,提升算法鲁棒性。自动驾驶系统可通过重建真实交通场景(如行人过马路、车辆变道)来增强感知能力。
4. 医学影像与运动分析
模型可用于重建人体关节运动的4D模型,辅助康复训练或运动生物力学研究。例如,从少量X光或MRI切片中还原心脏跳动的完整动态。
五、相关链接
GitHub代码库: https://github.com/Mars-tin/4D-LRM
项目主页:https://4dlrm.github.io/
总结
4D-LRM作为首个开源的大规模时空重建模型,通过4D高斯基元表示和Transformer架构,实现了从稀疏输入到高保真动态场景的重建能力。其少样本学习、实时推理和多行业适用性特点,为VR/AR、影视制作、工业仿真等领域提供了革命性工具。尽管在非线性运动处理和计算资源需求上仍存在局限,但该项目无疑推动了动态场景建模技术的边界,为AI驱动的4D内容创作树立了新标准。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4821.html


























