一、AudioGenie是什么?
AudioGenie 是由腾讯AI Lab与香港科技大学(广州)联合研发的无需训练的多智能体系统,专注于多模态到多音频生成(MultiModality-to-MultiAudio, MM2MA)任务。它能够从视频、图像、文本等多模态输入中,自动生成高质量、高保真度的复杂音频组合,包括音效、语音、音乐及混合音频。其核心创新在于通过双层智能体协作架构(生成团队与监督团队)和无训练范式,解决了传统音频生成模型面临的三大挑战:精细化理解不足、任务多样性难以应对、输出可靠性欠佳。
与其他依赖大规模训练数据的AI音频工具(如Claude、Gemini)不同,AudioGenie通过动态调用预训练的专家模型库(如语音合成、音乐生成等SOTA模型),结合任务分解与迭代优化机制,实现“零训练”的高效生成,显著降低开发成本(成本仅为传统方案的3%)。项目已开源,并配套发布了首个多模态音频生成评测基准MA-Bench(包含198个专业标注视频样本),在9项关键指标中均达到或超越当前最优水平(SOTA)。
二、功能特色
1. 多模态输入兼容性
AudioGenie支持视频、图像、文本及其组合输入,并能精准解析多模态信息中的时空与语义细节:
视频输入:自动捕捉画面动作(如“杯子落地瞬间”)并生成同步音效;
图像输入:根据静态场景(如“深夜自习室”)推理空间层次感,生成分层环境音;
文本输入:通过自然语言描述(如“科幻片机器人启动失败”)生成包含金属摩擦、电流杂音等细节的复合音效。
2. 全类型音频输出
系统可生成以下四类音频,并支持多类型混合输出:
音效:区分细节差异(如“新旧电梯运行声”);
语音:生成情感贴合、节奏自然的角色独白(如“老人回忆往事”的沙哑停顿);
音乐:根据场景需求(如“悬疑短片”)动态调整配乐风格与时长;
混合音频:实现多元素分层融合(如课堂场景中的讲课声、窃窃私语、鸟叫的空间分层)。
3. 无训练与低门槛设计
无需训练:通过动态调用预训练专家模型库(如Diffusion Transformer、Latent Diffusion等),避免传统模型对特定任务数据的依赖;
低代码接口:提供预设音效模板(如“恐怖电影常用组合”),用户可通过简单配置快速生成专业级音频。
4. 自我修正与高质量输出
试错迭代优化:基于“思维树(Tree-of-Thought)”流程,监督团队从质量、对齐度、美学等维度评估生成结果,自动触发修正或重试;
高保真度:在MA-Bench测试中,音频质量(MOS-Q 4.7/5)、时空对齐精度(0.1ms误差)、艺术表现力(MOS-Aesth. 4.86/5)均显著领先同类工具。
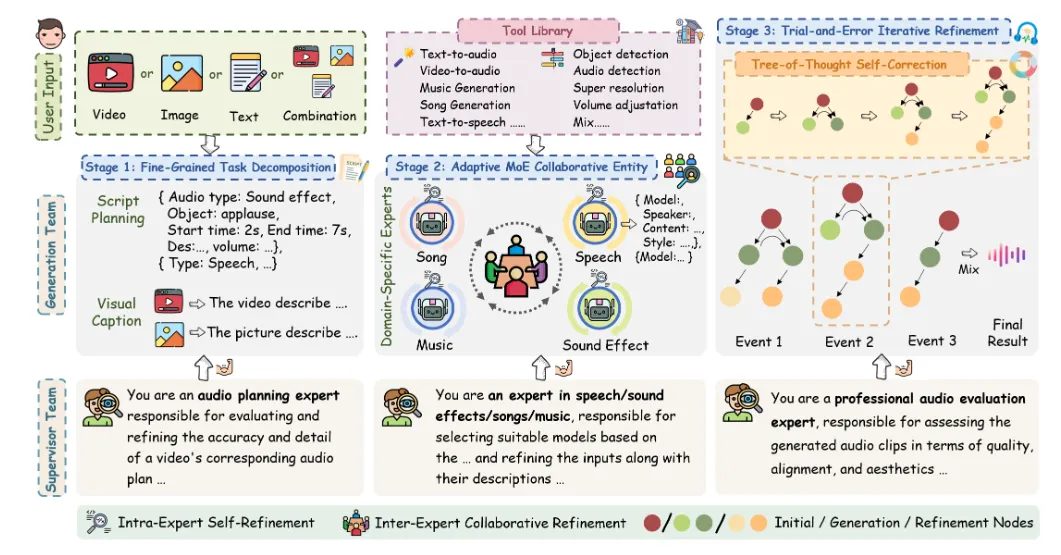
三、技术细节
1. 双层智能体协作架构
AudioGenie的核心由生成团队和监督团队组成,形成闭环工作流:
生成团队:
精细化任务分解模块:将输入拆解为结构化音频子事件(如“脚步声由远及近,起止时间2s-7s”),生成详细蓝图;
自适应混合专家(MoE)协作实体:根据子任务类型(音效、语音等)分配专家模型,通过“专家内自我修正”与“专家间协作修正”优化方案。
监督团队:
时空质检员:检查音频与输入的画面/文本在时间(动作同步)和空间(声源方位)上的一致性;
迭代优化引擎:基于评估结果(如“浪频与画面波纹不符”)动态调整参数,直至输出达标。
2. 关键技术创新
精细化任务分解:通过多模态分析(如视频中的物体检测、文本语义解析)生成带时间戳、内容描述的音频事件序列;
自适应模型调度:专家模型库包含语音合成(如TTS)、音乐生成(如DiffRhythm)、音效合成(如FoleyCrafter)等SOTA工具,按需动态组合;
思维树迭代优化:候选音频经过多轮评估-修正循环,确保最终输出的自然度与细节表现力。
3. 性能验证与基准测试
研究团队构建的MA-Bench包含198个视频样本,覆盖电影场景、自然环境、动作音效等8类任务。AudioGenie在客观指标(如内容对齐精度PC 5.503)和主观体验(MOS评分)上全面领先(见表1)。
四、应用场景
1. 影视与游戏开发
影视后期:自动生成与画面情绪匹配的背景音乐(如“暴雨场景的雨声+雷鸣”),配音效率提升40倍;
游戏音效:根据场景图(如“古旧书房”)生成动态音效包(木质地板声、机关触发音),成本降至零。
2. 虚拟人与交互设计
虚拟主播:生成情感丰富的语音(如“孩童撒娇的奶音拖长”),告别机械音;
VR/AR:实时生成3D音场(如故宫VR中青砖位置差异回声)。
3. 教育与无障碍服务
在线课件:为实验步骤自动生成连贯音效(如“试管碰撞+液体沸腾”),提升学生知识点吸收率25%;
视障辅助:通过图像生成详细音频描述,增强信息可访问性。
4. 广告与短视频创作
品牌音效:快速匹配调性(如“奶茶广告的温暖杯碰撞声”),节省80%时间;
自媒体内容:1分钟生成vlog分层音效(如“晨间厨房的切菜声+煎蛋声”)。
五、相关链接
项目主页:https://audiogenie.github.io/
论文地址:https://arxiv.org/abs/2505.22053
总结
AudioGenie通过创新的无训练多智能体架构,实现了从多模态输入到高质量音频生成的端到端解决方案。其核心价值在于降低专业音频创作门槛(无需训练、低代码)、提升生成效率(40倍速度提升)与保证输出可靠性(自我修正机制),在影视、游戏、教育等领域展现出变革性潜力。该项目的开源与基准测试发布,进一步推动了MM2MA领域的技术标准化与应用普及。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/audiogenie.html





开源的一款融合全景视频生成与3D重建的统一框架")




















