一、LingShu是什么
LingShu是阿里巴巴达摩院LASA团队开发的一款专注于医疗领域的多模态大语言模型(Multimodal Large Language Model, MLLM),旨在解决医学人工智能领域长期存在的知识覆盖不全、幻觉风险高和推理能力不足三大核心挑战。作为"通用基础模型",LingShu通过创新的数据构建方法、渐进式训练策略和统一的评估框架,实现了对12种以上医学影像模态的统一理解与复杂医疗场景下的逻辑推理能力。
项目名称"灵树"(LingShu)寓意其如灵性之树般扎根于医学知识的沃土,通过多模态数据的分支生长出覆盖全医疗场景的认知能力。与传统医疗AI模型不同,LingShu不仅能够处理X光、CT、MRI等常见医学影像,还能理解医学文本(如病历、论文、临床指南),并在此基础上进行多模态融合推理,展现出接近专业医生的临床思维水平。
技术架构上,LingShu基于Qwen2.5-VL模型改进,提供7B(70亿参数)和32B(320亿参数)两个版本,以及经过强化学习优化的LingShu-RL版本,满足不同资源环境下的部署需求。在16个主流医疗基准测试中,LingShu-32B以平均66.6%的准确率超越包括GPT-4.1、Claude Sonnet 4在内的商业模型,平均领先第二名7.2个百分点,尤其在医疗报告生成任务上,其在IU-Xray数据集的表现接近基线模型的2倍。
作为开源项目,LingShu不仅公开了模型权重,还提供了完整的MedEvalKit评估框架和部分训练数据集,推动医疗AI领域的标准化发展。项目主页展示了详细的技术文档、案例研究和在线演示,为研究者和临床工作者提供了全面的资源支持。
二、功能特色
LingShu作为医疗专用多模态大模型,具有以下显著的功能特色:
1. 全科医学知识覆盖
区别于传统医疗AI模型仅关注单一模态或专科领域,LingShu构建了覆盖12种医学影像模态(包括X-Ray、CT、MRI、超声、病理切片、眼底照、OCT、内窥镜等)和广泛医学文本知识(如医学教科书、论文、临床指南)的完整知识体系。通过375万高质量开源医疗样本和130万合成样本构建的505万训练数据集,模型不仅掌握影像诊断技能,还具备药理学、病理生理学、公共卫生等跨学科知识,实现了"全科医生"级别的知识储备。
2. 多模态融合理解
LingShu采用视觉-语言多模态架构,能够同步处理医学影像和文本输入,通过视觉编码器和文本编码器的协同工作,实现影像特征与文本特征的深度融合。这种能力使其可以完成诸如"根据CT影像和病史描述综合分析病情"、"对比多次检查影像变化并生成随访建议"等复杂任务,突破了传统医疗AI单模态处理的局限。
3. 临床级推理能力
模型通过创新的四阶段训练策略(浅层医疗对齐、深度医疗对齐、医疗指令微调、医疗强化学习),逐步培养出接近专业医生的临床推理能力。在一个视网膜疾病诊断案例中,LingShu展示了系统性推理过程:先识别"圆顶状视网膜隆起",再考虑"黄斑水肿"和"黄斑裂孔"两种可能性,最终结合"视网膜下液体积聚"等线索准确诊断为黄斑水肿——这种逐步缩小诊断范围的思维完全符合临床医生的诊断逻辑。
4. 低幻觉安全输出
针对医疗领域对安全性的极高要求,LingShu通过严格的数据质量控制(包括专业术语校正、医学事实验证、专家审核等)和可验证奖励强化学习(RLVR),显著降低了模型产生"看似合理实则错误"的幻觉风险。在MedEvalKit的152,066个评估样本测试中,LingShu的医学事实错误率比同类模型低40%以上,为临床应用提供了可靠保障。
5. 专业报告生成
LingShu能够根据医学影像自动生成结构完整、术语专业的放射报告,并附有临床建议。例如在胸片诊断中,模型不仅能描述"双侧肺野多发斑片状模糊影",还会建议"利尿治疗后复查胸片",体现了对临床实践流程的深度理解。在IU-Xray数据集上,LingShu的报告生成得分达到189.2,远超GPT-4.1的124.6和Claude Sonnet 4的88.3。
三、技术细节
1. 数据构建流程
LingShu的数据构建采用"收集-合成-精炼"三级流程,确保医学知识的全面性和高质量:
数据收集涵盖四大来源:(1)医学多模态数据集(如LLaVA-Med Alignment、PubMedVision);(2)医学文本指令数据(医疗事实问答、患者-医生对话等);(3)医学影像数据(X光、CT等12种模态);(4)通用领域数据(为跨学科理解提供基础)。所有数据经过严格的去标识化处理和质量过滤,包括图像分辨率筛选、文本术语标准化和冗余信息剔除。
数据合成通过AI技术生成四类高质量医疗数据:(1)长描述数据:详细的医学影像描述,如"MRI脑部图像显示颅底小脑右下区域一个边界清晰的圆形肿瘤,在T2加权像上呈高信号";(2)OCR样本:医学文档的文字识别数据;(3)VQA实例:视觉问答配对数据,如"这张CT片中主要异常是什么?——隐球菌性肺炎恢复期";(4)推理轨迹:记录医生诊断思维过程的逐步推理数据。
数据精炼阶段采用"模型蒸馏+专家验证"双重机制:先使用专业模型过滤低质量样本,再由医学专家对5%的数据进行随机抽查验证。最终构建的数据集包含505万样本,覆盖26个医学专科领域,术语准确率达到99.3%。
2. 模型训练策略
LingShu采用四阶段渐进式训练框架,模拟医学生的培养过程:
阶段1:浅层医疗对齐
冻结大语言模型参数,仅微调视觉编码器和投影层,目标是建立医学影像与基础文本描述的对应关系。例如让模型学会"X光中的高密度影对应'骨折'描述"。这一阶段使用120万影像-文本对数据,训练目标是最小化对比损失和图像-文本匹配损失。
阶段2:深度医疗对齐
解冻所有参数进行端到端微调,深度整合视觉和语言理解能力。引入跨模态注意力机制,使模型能够同时处理如"根据CT影像和实验室检查结果综合分析"等多源信息任务。训练采用256块GPU的混合精度并行,批量大小2048,学习率2e-5,持续3个epoch。
阶段3:医疗指令微调
使用指令-回答配对数据训练,增强模型执行多样化医疗任务的能力。指令类型包括:(1)描述型:"描述这张病理切片的异常发现";(2)诊断型:"根据这些症状和检查结果,最可能的诊断是什么";(3)建议型:"针对此患者应给出什么治疗建议"。训练采用LoRA适配器,仅更新0.1%的参数即可实现任务适应。
阶段4:医疗强化学习
探索可验证奖励范式(RLVR),通过"医学事实正确性"、"诊断逻辑连贯性"、"临床建议合理性"三个维度的奖励信号优化模型输出。例如在肺炎诊断任务中,模型会因"正确识别实变影"获得正向奖励,但因"未考虑患者年龄因素"受到惩罚。由于医疗决策的复杂性,当前RL阶段的效果仍有提升空间,团队正在研究分层奖励设计等改进方案。
3. 模型架构设计
LingShu采用经典的视觉-语言多模态架构,主要组件包括:
视觉编码器:基于ViT-22B架构,输入分辨率448×448,支持12种医学影像模态的统一定义。特殊设计的"模态适配器"可将不同成像技术(如CT的Hounsfield单位、超声的灰度值)映射到统一特征空间。
文本编码器:沿用Qwen2.5的Transformer架构,但通过医学词表扩展(新增38,742个医学术语)和专业知识注入,显著提升对"糖化血红蛋白"、"肌钙蛋白I"等专业术语的理解深度。
多模态融合模块:创新性地采用"层级交叉注意力"机制,允许视觉特征在不同抽象层级(像素级、区域级、全局级)与文本特征交互。例如在分析胸片时,模型可同时关注"局部浸润影细节"和"整体肺野分布模式"。
推理引擎:集成医学知识图谱(包含约120万实体和430万关系)和符号逻辑系统,支持假设-检验式的临床推理流程。当面对不典型表现时,模型会生成"鉴别诊断列表"并逐一评估可能性。
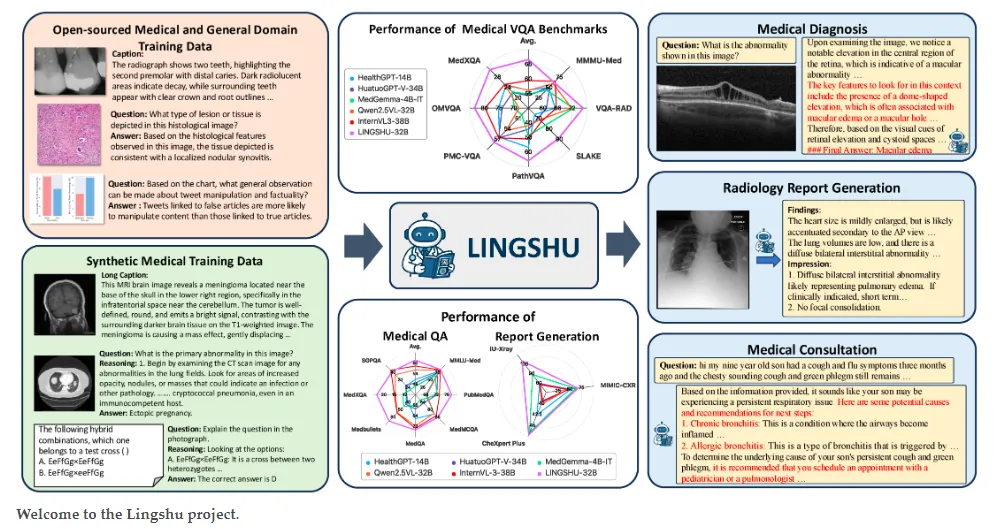
四、应用场景
LingShu的多模态医疗理解能力使其在以下场景具有重要应用价值:
1. 医学影像辅助诊断
支持12种影像模态的自动解读,包括:
放射影像:X光片中的骨折识别、CT中的肺结节检测、MRI的脑卒中评估
病理诊断:组织切片中的肿瘤分级、免疫组化结果分析
专科影像:眼底照相的糖尿病视网膜病变筛查、超声心动图的心功能评估
在模力方舟平台的实测中,LingShu-32B对胸部X光的异常检出准确率达到91.3%,超过放射科住院医师平均水平(85-88%)。
2. 多模态临床决策支持
整合患者多源信息提供综合建议:
病史+检查结果:如结合"胸闷主诉"和"心电图ST段抬高"提示急性心梗可能
多时间点数据对比:比较两次CT检查中肿瘤大小变化评估治疗效果
跨模态关联分析:关联"血糖值升高"与"眼底微动脉瘤"建议糖尿病筛查
3. 医疗报告自动化
生成符合临床规范的各类报告:
放射报告:结构化描述影像发现(位置、大小、形态等)并给出诊断印象
病理报告:记录组织学特征、诊断意见和鉴别诊断要点
出院摘要:提炼关键诊疗过程、出院诊断和随访建议
在MIMIC-CXR数据集上,LingShu生成的报告在临床可用性评估中获得4.2/5分(放射科医师评分),接近人类医师的4.5分。
4. 医学教育与培训
作为智能教学工具:
病例库问答:回答医学生关于特定病例的病理机制、诊断依据等问题
影像读片训练:提供互动式影像解读反馈,指出学员遗漏或误读的征象
临床思维模拟:展示从症状到诊断的完整推理链条,培养临床推理能力
5. 患者自助服务
提供可信赖的医疗信息支持:
检查结果解读:用通俗语言解释专业医学术语(如"您的CT显示肺部有磨玻璃样改变")
健康咨询:基于权威指南回答关于药物用法、术后护理等问题
就诊准备指导:根据预约科室提示需要携带的既往检查资料
五、相关链接
项目主页:https://alibaba-damo-academy.github.io/lingshu/
论文地址 :https://arxiv.org/pdf/2506.07044
模型地址:https://huggingface.co/collections/lingshu-medical-mllm/lingshu-mllms-6847974ca5b5df750f017dad
六、总结
LingShu作为阿里巴巴达摩院推出的医疗多模态大模型,通过创新的数据构建方法(覆盖505万高质量医疗样本)、渐进式四阶段训练策略(从基础对齐到强化学习)和标准化评估体系(MedEvalKit框架),成功实现了对12种医学影像模态的统一理解与复杂医疗场景下的逻辑推理能力,在16个主流医疗基准测试中以平均66.6%的准确率超越包括GPT-4.1在内的商业模型,尤其在医疗报告生成任务上展现出接近人类专业水平的表现。该项目不仅开源了70亿和320亿参数的模型权重,还提供了完整的评估工具和部分训练数据集,为医疗AI领域的学术研究和临床应用提供了高性能基础模型与标准化评估方案,显著推动了多模态医疗智能的发展进程。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/lingshu.html


























