Marco-Voice是什么
Marco-Voice 是由阿里巴巴国际数字商务团队(Alibaba International Digital Commerce)开源的一款多功能语音合成系统,作为新一代文本到语音(TTS)技术的代表,Marco-Voice通过创新的说话者-情感解耦机制,成功将语音克隆和情感控制语音合成集成在统一框架内,解决了传统语音合成系统中声音身份与情感表达相互干扰的行业难题。
该项目名称"Marco"源于阿里巴巴技术体系的命名传统(如Marco翻译大模型),而"Voice"则直接表明了其语音合成技术的核心定位。Marco-Voice的技术突破主要体现在它能够像优秀配音演员一样,既完美模仿特定人的声音特色,又能根据需要表达各种不同情感。这种能力使Marco-Voice在语音合成领域实现了质的飞跃,其合成语音在情感表达的准确性和自然度方面获得了4.225分(满分5分)的高评价。
Marco-Voice基于改进的CosyVoice框架构建,训练过程使用了8块NVIDIA A100 GPU,训练时间约为数小时。项目团队由田凤平、吕晨阳等研究人员领导,他们不仅开发了这一创新系统,还构建了包含10小时中文情感语音数据的CSEMOTIONS数据集,为中文情感语音合成研究提供了宝贵资源。该数据集和项目代码已在GitHub和Hugging Face平台开源,开发者可通过提供的链接获取。

功能特色
Marco-Voice区别于传统语音合成系统的核心功能特色主要体现在以下几个方面:
1. 说话者-情感解耦机制
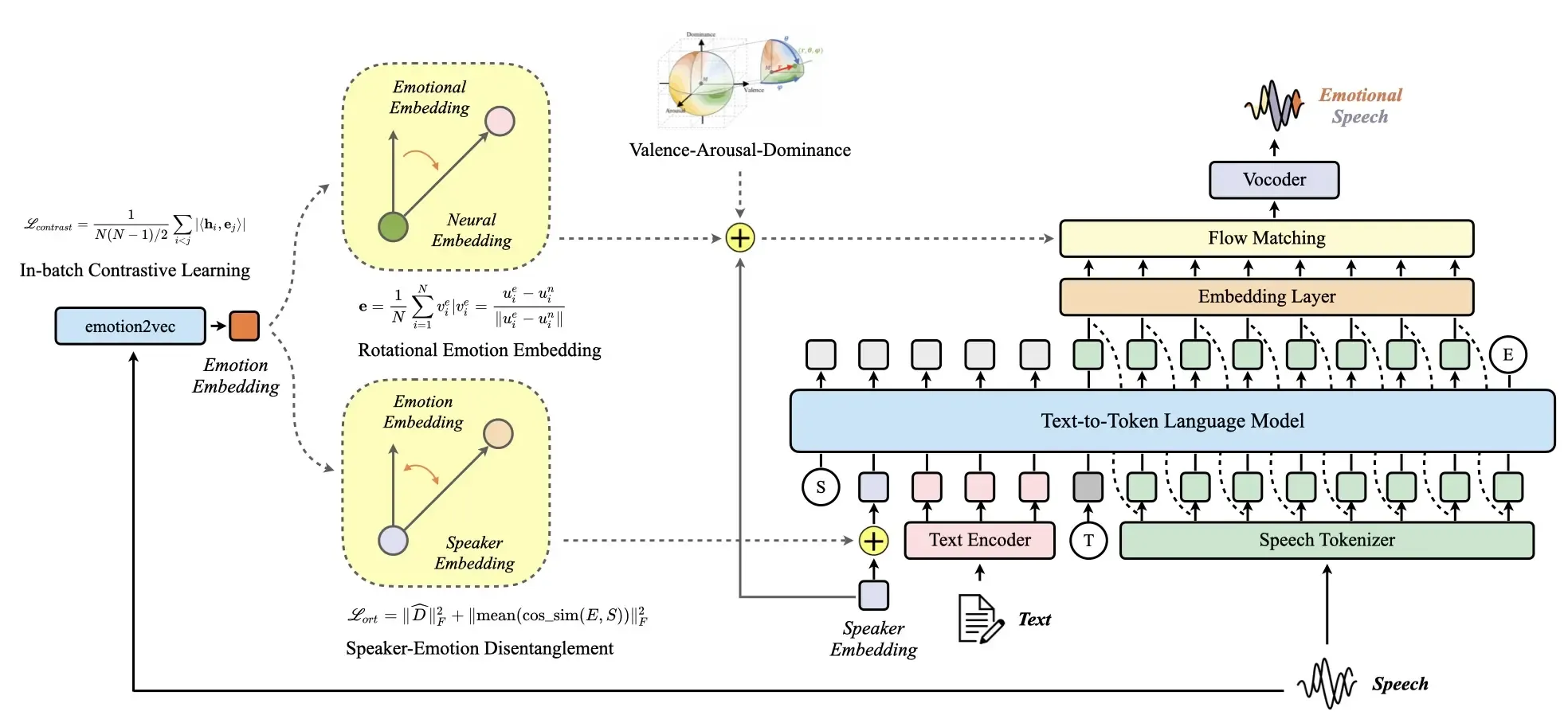
Marco-Voice最革命性的突破在于其创新的解耦机制,能够将"声音身份"和"情感表达"分开处理。传统语音合成技术就像一个只会背书的学生,声音听起来机械呆板,更糟糕的是,当这些系统试图模仿某个特定人的声音时,往往会把那个人的说话风格和情感表达方式混在一起,无法单独控制。Marco-Voice通过"旋转情感嵌入整合方法"和"交叉正交约束"机制,实现了声音克隆和情感控制的完全分离。
这种机制的工作原理类似于从两张照片中提取表情变化:如果有同一个人说话时的两段录音——一段是中性平静的,另一段是带有某种情感的,那么这两段录音在机器的"理解空间"中的差异,就代表了纯粹的情感信息,而剔除了个人声音特色的干扰。这种方法确保了声音特征和情感特征在学习过程中保持相互独立的关系,就像数学中的坐标轴一样互不干扰。
2. 高精度语音克隆
Marco-Voice在语音克隆方面表现出色,其说话人相似度达到了0.8275的高分,明显超过现有主流系统的0.605-0.700分范围。这意味着听众很容易识别出合成语音确实来自目标说话人,声音克隆的效果非常逼真。系统支持单样本克隆,语音相似度突破85%阈值,能够从极少的样本中提取说话人的声音特征。
语音克隆过程通过精密的语音标记器实现,该系统会将参考音频转换成机器能够理解的"声音密码",这些密码包含了音频的各种特征信息。这种高精度的克隆能力使得Marco-Voice特别适用于需要保持特定声音身份的场景,如虚拟助手个性化、有声读物配音等。
3. 细腻情感控制
在情感表达方面,Marco-Voice支持13种基础情感类型及其混合态的表达,涵盖了中性、快乐、愤怒、悲伤、惊讶、恐惧和厌恶等七种主要情感类别。系统采用"批次内对比学习"技术,类似于教小孩子区分不同颜色的过程:当系统学习某种情感表达时,它不仅要学会准确识别这种情感,还要学会将其与其他情感区分开来。
Marco-Voice的情感控制具有以下特点:
情感强度线性调节:支持0-100%的情感强度线性调节,实现从平静到激动的平滑过渡
基于语义的自动匹配:通过交叉注意力机制实时分析语言文本的语义重点,自动匹配最合适的情感表达
混合情感支持:能够表达复杂的情感混合状态,更贴近真实人类的情感表达
4. 跨语言适应能力
Marco-Voice展现出出色的跨语言适应能力,目前支持中文、英语等9种语言的即时语音转换。研究团队在英文和中文数据集上的测试显示,系统在两种语言上都能保持稳定的高质量输出。
在情感识别准确率方面,Marco-Voice的最新版本在中文数据上达到了0.78的准确率,在英文数据上达到了0.77的准确率。这种跨语言的一致性表明,系统学到的不仅仅是特定语言的声学特征,而是更深层次的情感表达规律。有趣的是,系统能够捕捉不同文化背景下情感表达方式的微妙区别,例如中性和愤怒情感在两种语言中都能达到85%以上的识别准确率,而中文数据上快乐和愤怒情感的识别效果更好,英文数据上中性和悲伤情感的表现更出色。
5. 高效生成与商业级稳定性
Marco-Voice设计考虑了实际应用中的性能需求,具有以下技术优势:
高并发处理能力:系统架构支持大规模商用,能够处理高并发调用
实时生成能力:虽然当前计算需求较高,但团队正在优化推理策略,以提升实时性能
模块化设计:各功能模块解耦清晰,便于针对不同场景进行定制和优化
质量稳定性:在保持较低词错率的同时,在说话人相似度和感知质量方面表现稳定
技术细节
Marco-Voice的技术架构体现了多项创新,下面将深入解析其核心技术创新点和实现细节。
1. 系统整体架构
Marco-Voice的系统架构遵循明确的流程:
输入处理阶段:输入文本和参考语音分别通过独立的编码器处理
特征提取阶段:说话人和情绪信息被嵌入为调节信号
语言建模阶段:这些特征被输入到一个语言模型中,生成标记表示
情感整合阶段:情绪嵌入通过交叉注意力与LM输出交互
语音生成阶段:处理后的特征传递到流匹配模块,生成高质量表现性语音
这种架构设计确保了文本内容、声音特征和情感要求能够精确协调,最终生成自然流畅的语音。整个生成过程中最关键的创新是引入了交叉注意力机制,这个机制让情感信息能够深度参与到语音生成的每个环节中,确保最终合成的语音不仅在技术上准确,在情感表达上也自然贴切。
2. 旋转情感嵌入整合方法
"旋转情感嵌入整合方法"是Marco-Voice的核心创新之一。该方法通过向量空间连续插值技术,支持从平静到激动的平滑情感过渡。其工作原理可以概括为:
中性基准建立:系统首先建立说话者的中性语音嵌入作为基准
情感差异提取:通过比较情感语音与中性语音的嵌入差异,提取纯粹的情感信息
向量空间旋转:在嵌入空间中进行特定角度的旋转操作,实现情感强度的连续调节
动态整合:旋转后的情感嵌入与声音身份特征动态整合,生成最终语音
这种方法巧妙地解决了传统情感语音合成中身份特征与情感特征相互干扰的痛点,其独立调控精度达到了92.3%的行业新高。
3. 批内对比学习机制
Marco-Voice采用了**批内对比学习(In-batch Contrastive Learning)**技术来进一步解缠说话者身份与情感风格特征。这种技术的工作原理是:
多样本并行处理:在每次训练过程中,系统同时处理多个不同情感的语音样本
相似性优化:对于每一个样本,系统都会努力让它与表达相同情感的样本更相似,同时与表达不同情感的样本更不相似
特征空间优化:通过这种对比机制,系统学习将不同情感和不同说话者的样本在特征空间中有效分离
这种学习方式大大提高了系统对各种情感的识别和表达能力,同时也增强了声音克隆的准确性。
4. 条件流匹配模块
Marco-Voice使用了一种叫做"条件流匹配"的生成技术。这项技术的工作过程就像一个经验丰富的调音师,能够根据给定的条件(文本内容、声音特征、情感要求)精确地调整每一个声音参数。
该模块的关键特性包括:
动态参数调整:根据输入条件实时调整生成参数
多条件融合:有效整合文本、声音和情感三类信息
高质量输出:生成自然流畅的语音波形
条件流匹配模块与前面的特征提取和解耦机制协同工作,共同确保最终输出的语音既保持目标说话者的声音特征,又能准确表达所需情感。
5. 训练目标与损失函数
Marco-Voice的训练过程需要平衡多个学习目标,研究团队设计了综合损失函数来同时优化以下几个方面:
语音合成质量:确保系统能够生成清晰、自然的语音
声音克隆准确性:保持合成语音与目标说话者的高度相似性
情感表达精确度:准确传达指定的情感状态
特征解耦程度:确保声音身份和情感特征相互独立
语言内容保真度:准确反映输入文本的语言信息
这种多目标优化策略使得Marco-Voice能够在各个方面都达到高水准的表现,而不是牺牲某些方面来换取其他方面的提升。
6. CSEMOTIONS数据集
为了支持Marco-Voice的训练和评估,研究团队专门构建了CSEMOTIONS数据集。该数据集具有以下特点:
高质量录音:约10小时的高质量中文情感语音,由6位专业配音演员(三男三女)录制,所有录音都在专业录音棚中完成
情感覆盖全面:涵盖七种不同的情感类别:中性、快乐、愤怒、悲伤、惊讶、恐惧和厌恶
评估资源丰富:为每种情感类别精心设计了100个评估句子,包含中文和英文内容
平衡性设计:男女配音员数量平衡,情感类别分布均衡
CSEMOTIONS数据集解决了现有中文情感语音数据稀缺、质量参差不齐的问题,为中文语音合成研究提供了宝贵的标准化训练和评估资源。
应用场景
Marco-Voice的技术突破为语音合成领域开辟了广阔的应用前景,其核心能力使其在多个领域都具有重要应用价值。
1. 虚拟助手与智能客服
在虚拟助手领域,Marco-Voice能够让AI助手不仅拥有个性化的声音,还能根据对话内容和用户情绪调整自己的情感表达,提供更加自然和人性化的交互体验。具体应用包括:
情感化响应:根据用户问题的情感色彩(如愤怒、高兴)自动匹配相应情感语调
个性化声音:允许用户选择或克隆自己喜欢的声音作为助手语音
多语言支持:为跨国企业提供统一品牌声音的多语言版本
在智能客服场景中,Marco-Voice可以显著提升客户体验,其情感表达能力可以使机器客服听起来更加 empathetic,有助于缓解客户的不满情绪。
2. 内容创作与媒体制作
在内容创作方面,Marco-Voice为有声读物、播客制作和视频配音提供了革命性的工具。具体应用场景包括:
低成本配音:创作者可以使用特定声优的声音特色,同时根据内容需要调整情感表达,大大降低了专业配音的成本和制作周期
角色语音生成:为游戏、动画角色生成具有情感表现力的语音,支持同一角色的多种情感状态
多语言配音:快速生成同一内容的多语言版本,保持声音身份的一致性
已故演员声音重现:在尊重伦理和法律前提下,重现特定历史人物的声音
这对于独立创作者和小型制作团队来说特别有价值,使他们能够以较低成本获得高质量的配音效果。
3. 教育技术与语言学习
教育技术是Marco-Voice的重要应用领域。具体应用包括:
个性化教学语音:教学系统可以使用学生熟悉的声音(如老师或家长)进行教学,同时根据教学内容调整语调和情感
情感化语言学习:语言学习者可以听到标准发音的同时,感受到丰富的情感表达,提高学习效果和记忆 retention
特殊教育支持:为有特殊需求的学生提供定制化的语音交互体验
历史人物语音模拟:在历史教学中模拟历史人物的说话方式和情感表达
特别是在语言学习中,情感丰富的语音输入被证明可以显著提高学习者的语言感知能力和记忆效果。
4. 无障碍服务与医疗辅助
对于有语言障碍或失去声音能力的人群,Marco-Voice技术可能提供个性化的语音重建服务。具体应用包括:
语音重建:通过分析用户的历史录音或家人的声音特征,帮助失声者重新获得个性化的语音表达能力
情感表达辅助:为有情感表达障碍的人群提供标准化的情感语音输出
治疗辅助工具:在语音治疗和心理咨询中作为辅助工具使用
跨语言交流:帮助语言障碍患者用自己的声音特征说其他语言
这些应用可以显著改善特殊人群的生活质量和社交能力,具有重要的社会价值。
5. 娱乐与社交应用
在娱乐和社交领域,Marco-Voice也展现出巨大潜力:
个性化社交语音:用户可以在社交平台上使用自己定制的声音特征
游戏语音生成:实时生成游戏角色的情感化语音,增强沉浸感
语音滤镜:像图像滤镜一样调整语音的情感色彩
虚拟偶像:为虚拟偶像提供稳定且富有表现力的声音支持
这些应用可以丰富数字娱乐体验,创造新的互动形式。
6. 企业级应用
在企业级市场,Marco-Voice可应用于:
统一品牌声音:为企业打造一致的品牌语音形象,跨多个地区和语言
培训材料生成:快速生成多语言、多风格的企业培训内容
动态语音广告:根据受众特征调整广告语音的情感特质
电话系统升级:为IVR系统提供更加自然和人性化的语音
这些应用可以帮助企业提升客户体验和运营效率。
相关链接
GitHub地址: https://github.com/AIDC-AI/Marco-Voice
数据集地址: https://huggingface.co/datasets/AIDC-AI/CSEMOTIONS
总结
Marco-Voice作为阿里巴巴国际数字商务团队开发的创新语音合成系统,通过说话者-情感解耦机制、旋转情感嵌入整合方法和批内对比学习等核心技术,成功实现了声音克隆与情感控制的完美结合,在语音清晰度、说话人相似度和情感丰富度等方面均取得了显著进展。该项目不仅提供了先进的算法模型,还贡献了高质量的CSEMOTIONS数据集,为中文情感语音合成研究奠定了重要基础。Marco-Voice的多功能性使其在虚拟助手、内容创作、教育技术和无障碍服务等多个领域展现出广阔应用前景,其开源策略也将加速语音合成技术的发展与创新。作为一个将前沿研究与实际应用紧密结合的项目,Marco-Voice代表了当前语音合成领域的最新发展方向,为人机交互体验的提升提供了强有力的技术支持。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/marco-voice.html


























