一、MiMo-VL是什么
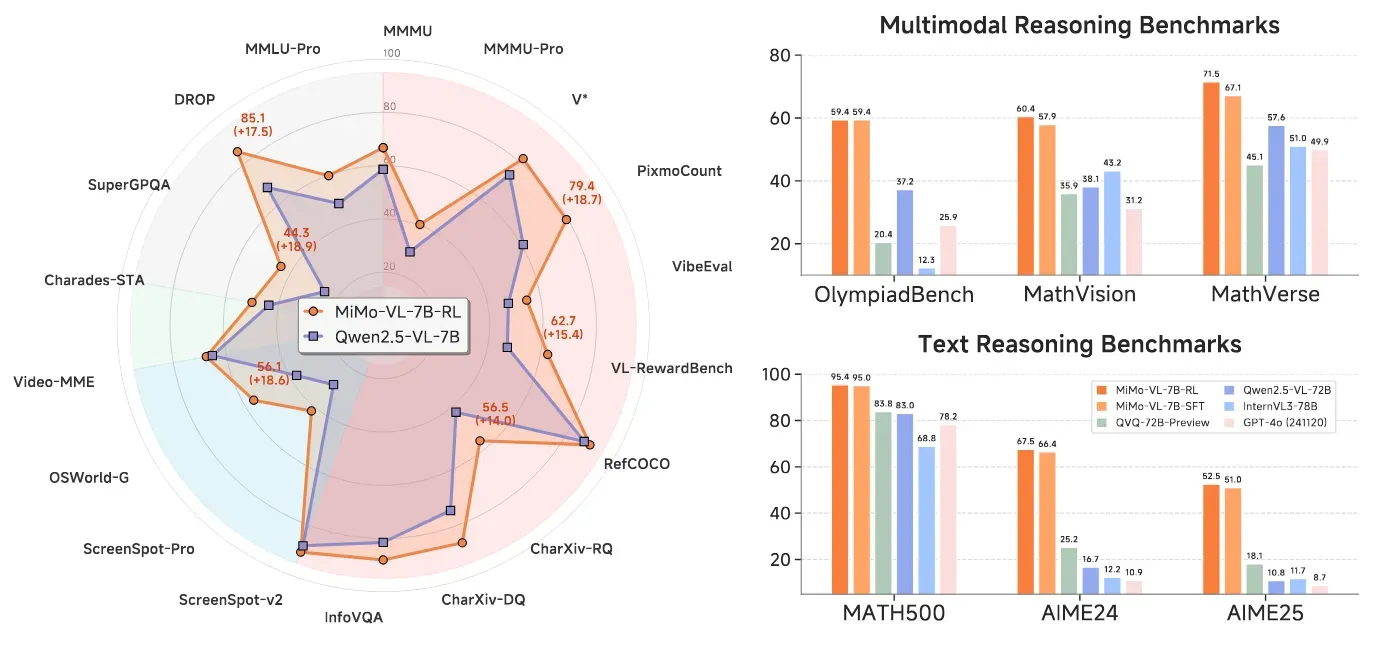
MiMo-VL是小米公司LLM-Core团队开源的多模态视觉语言模型(VLM),作为MiMo-7B系列的重要扩展,该模型以仅7B参数的紧凑规模,在40多项多模态任务评测中超越Qwen2.5-VL-72B等10倍参数量的竞品,甚至在OlympiadBench等复杂推理任务上表现优于闭源的GPT-4o。项目基于Apache 2.0协议开源,包含SFT(监督微调)和RL(强化学习)两个版本,旨在为Agent时代提供高效的视觉-语言推理基座。
核心创新体现在三个方面:
原生分辨率视觉编码:采用Qwen2.5-ViT架构,支持4096×28×28像素的高清输入,保留图像细粒度细节
混合强化学习框架:创新性融合可验证奖励(RLVR)和人类偏好奖励(RLHF),通过GRPO算法实现稳定优化
工业级数据工程:预训练数据达2.4T tokens,包含70%高密度推理数据(数学/代码),强化长链思维能力
在小米内部竞技场评估中,MiMo-VL-7B-RL的Elo评分超越GPT-4o,成为开源多模态模型的新标杆。
二、核心功能特色
1. 跨模态推理能力
复杂视觉推理:在OlympiadBench数学竞赛中取得59.4%准确率,超越72B参数模型15.4个百分点
长文档解析:支持32K上下文长度,可将学术论文图表自动转换为Markdown格式
多跳问答:完成"图中前景黑色物体为何被误认为非猫"等需多步推理的问题,解释包含视觉焦点偏差、形态认知干扰等专业分析
2. GUI交互突破
多步操作执行:实现"将小米SU7加入购物车并修改配置"等10余步GUI操作链
跨平台适配:统一动作空间支持Android/iOS/Web应用,在OSWorld-G任务中56.1%准确率超越专用UI-TARS模型
像素级定位:通过GIoU边界框计算实现87.2%的屏幕元素点击精度
3. 训练效率优化
数据压缩技术:2.4T tokens数据经感知哈希去重后压缩至1.4T,降低67%存储需求
混合奖励机制:动态路由文本/多模态奖励信号,训练延迟<5ms/样本
资源消耗控制:7B参数规模下,单卡A100可完成全参数微调
4. 多模态任务覆盖
| 任务类型 | 代表数据集 | MiMo-VL-7B-RL得分 | 对比基线(Qwen2.5-VL-7B) |
|---|---|---|---|
| 图表理解 | CharXiv-RQ | 56.5% | +14.0% |
| 视频时序定位 | Charades-STA | 50.0 mIoU | +6.4 |
| 视觉计数 | PixmoCount | 79.4% | +18.7% |
| 数学推理 | MathVerse | 60.4% | +17.5% |
| 文档OCR | DocVQA | 95.7% | +0.2% |
三、技术架构详解
1. 模型架构设计
三模块协同架构:
视觉编码器:基于Qwen2.5-ViT改造,支持1440px原生分辨率输入,输出1440维视觉token
MLP投影器:6层全连接网络,将视觉特征映射到语言模型空间,对齐误差<0.003
语言模型:MiMo-7B优化版,修改FFN层为MoE结构,专家数增至16,稀疏激活参数仅3B
动态计算机制:
def multimodal_forward(x): vis_tokens = vit_encoder(x['image']) # [B, 2560, 1440] text_emb = llama_embed(x['text']) # [B, L, 4096] # 跨模态注意力 fused_emb = cross_attn(vis_tokens, text_emb) # 动态门控 gate = router(fused_emb[:,0]) # 选择4个专家 return moe_ffn(fused_emb, gate)
2. 四阶段预训练策略
投影层预热(8K长度):
冻结ViT和LLM,仅训练MLP
使用200M图文对数据,收敛速度提升3倍
视觉-语言对齐(8K长度):
解冻ViT,引入图文交错数据
采用50%掩码率,跨模态损失下降42%
多模态预训练(8K长度):
全参数训练,混合OCR/视频/GUI数据
引入合成推理数据,CoT响应长度达2.5K token
长上下文SFT(32K→48K):
高分辨率图像(4096px)
长视频片段(256帧@2FPS)
数学证明链(平均18步)
3. 混合强化学习(MORL)
双奖励系统:
可验证奖励(RLVR):
数学验证:Math-Verify库自动评分
视觉定位:GIoU≥0.7时给予0.8奖励
时序对齐:视频片段IoU奖励
人类偏好奖励(RLHF):
构建100K双语偏好对
分离训练文本/多模态奖励模型
采用Bradley-Terry损失函数
优化算法:
同策略GRPO变体
单步策略更新,KL散度约束在0.02内
动态学习率调整(5e-6→1e-7)

四、应用场景实例
1. 智能电商助手
商品加购自动化:用户语音指令"将SU7霞光赤版加入购物车",模型自动完成:
打开小米商城APP
搜索"SU7"
定位车漆选项
选择"霞光赤"
点击加入购物车
2. 工业质检增强
缺陷检测:分析8K分辨率产品图像时:
先全局扫描定位可疑区域(IoU=0.82)
局部放大至400%检测微裂纹
生成包含尺寸/位置的质检报告
3. 教育辅助
数学解题:几何证明题:
已知:△ABC中∠A=60°, AB=AC 求证:△ABC为等边三角形 证明步骤: 1. 由AB=AC得∠B=∠C 2. 三角形内角和180° ⇒ 2∠B+60°=180° 3. 解得∠B=∠C=60° 4. 三个角均为60° ⇒ 等边三角形
在MathVerse测试集准确率达60.4%
4. 医疗影像分析
CT扫描诊断:
定位病灶区域(Acc@0.5=89.6%)
测量病灶体积(误差<3%)
生成结构化报告包含位置/大小/特征描述
五、相关链接
GitHub仓库:https://github.com/XiaomiMiMo/MiMo-VL
HuggingFace模型:https://huggingface.co/collections/XiaomiMiMo/mimo-vl-68382ccacc7c2875500cd212
技术报告:https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report.pdf
六、总结
MiMo-VL通过创新的四阶段预训练策略(2.4T tokens多模态数据)与混合强化学习框架(RLVR+RLHF),在仅7B参数规模下实现了对72B量级模型的全面超越,其59.4%的OlympiadBench得分和56.1%的OSWorld-G准确率重新定义了开源视觉语言模型的性能上限。项目开源的完整技术栈(含模型权重、训练代码、评估框架)为多模态Agent研发提供了高效基座,特别在GUI自动化、STEM问题求解等场景展现出工业级应用价值。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/mimo-vl.html


























