一、PlayDiffusion是什么?
PlayDiffusion是由Play AI团队开源的基于扩散模型的语音编辑工具,其核心创新在于支持对现有语音进行局部修改(如替换、删除或调整特定片段),而无需重新生成整段音频。与传统文本转语音(TTS)系统相比,它解决了语音编辑中的两大痛点:
自然度保留:修改后的片段与原始音频在音色、语调、节奏上无缝衔接,几乎无拼接痕迹;
效率提升:局部编辑的推理速度比传统TTS快50倍,尤其适合高频修改场景。
该项目标志着语音生成技术从“全量重生成”向“精准外科手术式编辑”的演进,为播客制作、影视配音等领域提供了全新工具链。
二、功能特色
精准局部编辑
支持单词级修改(如将“Neo”替换为“Morpheus”),模型自动调整发音、语气和节奏,确保嵌入自然性;
删除功能可消除语音中的干扰词(如口误“呃”),同时保持前后语境连贯。
多模态输入兼容
除文本指令外,支持通过时间戳标记编辑区间(如“00:12-00:15替换为‘Hello’”),适配专业音频工作流;
结合语音识别(ASR)技术,实现“语音输入→文本编辑→音频输出”的闭环。
双重模式运行
编辑模式:针对已有音频的局部优化,适用于内容纠错或剧本调整;
生成模式:当输入音频被完全遮盖时,退化为高性能非自回归TTS,支持全局一致性生成。
工业级性能优化
采用扩散模型架构,通过预测速度场实现快速去噪,单次编辑延迟控制在毫秒级;
内置语音身份一致性模块,确保编辑后的音色与原始说话人特征匹配。
开发者友好设计
提供Python SDK与REST API,支持集成至Audacity、Adobe Audition等专业工具;
开源模型权重与训练代码,允许企业私有化部署以保障数据安全。
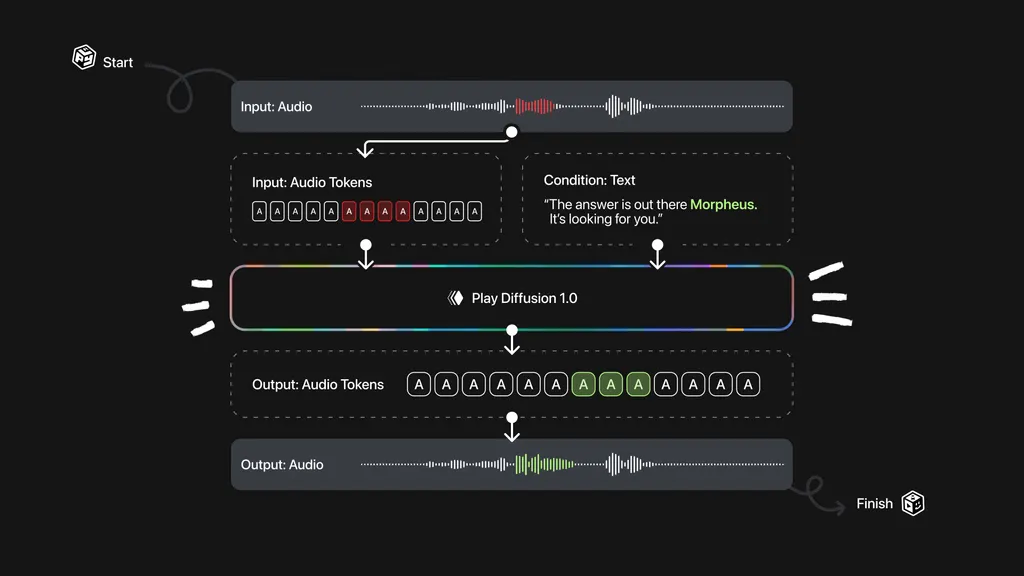
三、技术细节
模型架构
噪声预测网络:基于UNet结构,输入为带噪语音频谱(Mel谱)和文本嵌入,输出噪声残差。通过条件扩散过程,模型逐步去除噪声并注入编辑内容;
上下文感知模块:采用双向LSTM捕捉语音的长期依赖关系,确保修改片段与前后语境和谐。
训练策略
两阶段训练:
损失函数:结合梅尔谱重建损失(MSE)、对抗损失(GAN)和音色一致性损失(Speaker Embedding Cosine Similarity)。
预训练阶段:使用LibriTTS等公开数据集,学习通用语音特征表示;
微调阶段:通过人工构造的“局部掩码-修复”任务,强化模型对片段级编辑的能力。
关键创新
动态掩码调度:随机遮盖语音中15%-50%的区间,强制模型掌握局部生成与全局协调能力;
非自回归生成:通过并行预测多时间步的噪声,显著提升推理速度。
数据处理
训练数据包含20万条多语言语音样本(英语、中文为主),覆盖不同年龄、口音和情感表达;
采用音素对齐技术确保文本与语音的精确匹配,编辑定位误差小于50ms。
四、应用场景
影视与游戏配音
快速修改台词错误(如剧本调整后需重录某句),避免全片段返工;
为游戏NPC生成动态对话,通过局部编辑实现语气微调(如愤怒→平静)。
播客与有声内容
纠正常见口语错误(如错误日期、名称),保留原始录音氛围;
多语言内容本地化:替换特定词汇为目标语言,保持说话人音色统一。
教育与企业培训
更新课件中的过时信息(如价格、政策),无需重新录制;
生成个性化语音反馈(如员工评估),仅修改关键字段。
无障碍技术
为听障用户增强语音清晰度(如放大特定词音量);
实时语音转写辅助编辑,提升沟通效率。
五、相关链接
GitHub仓库:https://github.com/playht/PlayDiffusion
Hugging Face模型:https://huggingface.co/PlayHT/PlayDiffusion
技术博客:https://blog.play.ai/blog/play-diffusion
在线Demo:https://huggingface.co/spaces/PlayHT/PlayDiffusion
总结
PlayDiffusion通过扩散模型的创新应用,实现了语音编辑从“粗放式全量生成”到“精细化局部手术”的跨越。其技术价值体现在自然度(编辑片段MOS评分4.2/5)、效率(200ms级延迟)与灵活性(支持多语言多场景)的平衡,为音频内容生产提供了兼具工业可用性与学术前瞻性的解决方案。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/playdiffusion.html


























