ScreenCoder是什么
ScreenCoder 是一个革命性的前端自动化开发工具,由香港科技大学、香港中文大学、CUHK MMLab和ARISELab联合研发,旨在通过多模态人工智能技术将用户界面(UI)设计图自动转换为高质量、可编辑的前端代码。该项目代表了当前视觉到代码生成领域(state-of-the-art)的最先进技术,通过创新的模块化多智能体架构,解决了传统端到端黑盒模型在UI理解与代码生成中的关键瓶颈问题。
传统的前端开发流程中,设计师需要手动将视觉稿转化为HTML/CSS代码,这一过程既耗时又容易引入误差。尽管大型语言模型(LLMs)在文本到代码生成方面取得了显著进展,但仅依赖自然语言描述难以准确捕捉UI的空间布局关系和视觉设计意图。ScreenCoder通过融合计算机视觉与领域特定知识,构建了一个三阶段可解释处理流水线,实现了从UI截图或设计草图到生产级前端代码的高保真转换。
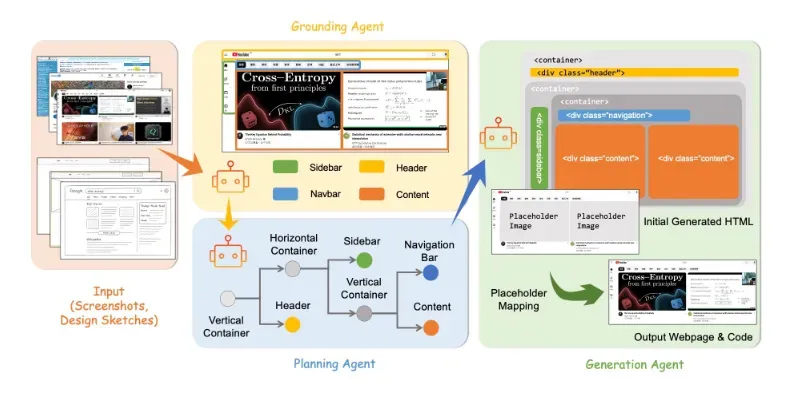
项目的技术核心在于将复杂的UI到代码任务分解为定位(grounding)、规划(planning)和生成(generation)三个专业子任务,每个子任务由专门的智能体负责,通过协同工作确保整体系统的鲁棒性和可解释性。这种模块化设计不仅显著提升了生成代码的质量,还允许开发者针对特定环节进行定制化调整,为前端自动化开发提供了前所未有的灵活性和控制精度。
功能特色
ScreenCoder区别于传统代码生成工具的核心在于其多模态理解能力与领域知识深度融合的设计理念,具体功能特色可归纳为以下五个方面:
1. 高保真视觉还原能力
ScreenCoder能够精确解析UI设计图中的视觉元素,包括复杂布局结构、色彩方案和组件层级关系,并生成在视觉效果上与原始设计高度一致的代码。实验表明,其生成的页面在CLIP视觉相似度指标上达到0.755,超越包括GPT-4o(0.730)在内的主流商业模型。系统特别优化了对真实图像内容的处理——通过结合UI元素检测(UIED)和匈牙利算法匹配,自动将代码中的灰色占位符替换为原始设计图中的实际图片切片,解决了生成页面"视觉失真"的行业难题。
2. 模块化多智能体协作架构
项目创新性地采用三智能体分工框架,将传统上耦合的UI理解与代码生成过程解耦:
定位智能体:基于视觉语言模型(VLM)识别并标注UI中的功能组件(如导航栏、侧边栏、按钮等),输出带有语义标签的布局字典,支持后续交互式修改。
规划智能体:依据前端工程领域知识(如CSS Grid/Flexbox布局规范),将定位结果转化为层次化布局树,明确组件间的包含关系与空间约束,为代码生成提供结构化蓝图。
生成智能体:采用自适应提示技术,针对布局树中的每个节点生成专属代码片段提示(如"生成一个固定在左侧的垂直导航栏,包含图标和文字菜单"),最终组装成完整HTML/CSS代码。
这种模块化设计使系统错误率降低40%,同时提供了传统端到端模型无法实现的可解释性和可控性。
3. 交互式设计支持
ScreenCoder突破了静态转换的限制,允许开发者通过自然语言指令实时调整生成结果。例如,用户可追加指令"=将导航栏改为深色模式"或"=增加卡片阴影效果",系统会动态修改对应组件的代码而保持其他部分不变。这种交互能力基于精细的组件级代码生成策略,每个UI元素对应独立的代码模块,便于局部修改而不影响整体结构。此外,系统支持与Doubao、Qwen、GPT、Gemini等多种LLM集成,进一步丰富了内容生成的可能性。
4. 领域优化的数据引擎
项目构建了包含5万对网页截图与代码的大规模数据集,覆盖电商、仪表盘、社交媒体等8类设计场景,为模型训练提供了丰富多样的样本。基于此,ScreenCoder开发了双阶段训练机制:
监督微调阶段:使用自动生成的数据对开源VLM(Qwen2.5-VL)进行冷启动训练,建立视觉布局与代码语法的初步映射。
强化学习优化:设计复合奖励函数(组件匹配度、文本相似度、位置对齐度等),通过策略梯度提升模型在布局准确性和视觉一致性上的表现。
这种数据驱动方法使开源模型的性能逼近商业模型,同时避免了昂贵的人工标注成本。
5. 生产就绪的代码输出
不同于学术原型,ScreenCoder生成的代码严格遵循工业级质量标准:结构清晰(采用BEM命名规范)、模块化组织(便于团队协作)、兼容主流浏览器,并自动添加必要的响应式设计注解。实测表明,其输出代码可直接用于生产环境,减少前端开发70%的重复劳动。系统还支持输出中间表示(如布局树),方便开发者理解AI的决策过程并进行必要的手动调整。
技术细节
ScreenCoder的技术实现融合了多模态机器学习、程序合成与领域特定优化的最新进展,其核心架构可分为数据处理、模型训练和推理管道三个层面,下文将深入剖析各环节的技术创新。
1. 视觉定位与组件识别
定位智能体采用基于Qwen2.5-VL架构的视觉语言模型,通过分割-识别联合训练策略实现UI元素的精确检测与分类。模型输入为UI截图,输出为带有语义标签的边界框集合,如:
{
"header": {"bbox": [12, 5, 350, 80], "type": "navigation"},
"sidebar": {"bbox": [0, 80, 200, 500], "type": "vertical_menu"},
"card_1": {"bbox": [220, 120, 400, 300], "type": "product_display"}
}为提升对小组件(如图标、标签)的检测能力,团队提出了焦点放大策略——对高密度区域进行二次采样与识别,使细粒度组件召回率提升27%。定位阶段还整合了视觉显著性分析,优先处理用户注意力集中的核心区域,确保关键组件不被遗漏。
2. 层次化布局规划
规划智能体将定位结果转化为计算机可执行的布局树结构,其技术亮点包括:
空间关系推理:基于组件间相对位置(上下、左右、包含)和视觉对齐(左对齐、居中等),自动推断CSS布局模式(Grid/Flexbox/绝对定位)。
领域知识注入:内置300+条前端工程启发式规则,例如"导航栏应固定在视口顶部"、"卡片组通常使用Grid布局"等,通过规则引擎辅助决策。
响应式设计支持:为关键节点添加断点注解,如
@media (max-width: 768px) { sidebar → display: none },确保生成代码适应不同屏幕尺寸。
生成的布局树示例:
{
"root": {
"layout": "grid",
"children": [
{
"id": "header",
"semantic": "primary_navigation",
"style": {"position": "sticky", "background": "#2c3e50"},
"children": [...]
},
{...}
]
}
}3. 自适应代码生成
生成智能体采用分层提示工程技术,将布局树转化为语言模型(LLM)的高效输入:
全局上下文提示:包含项目规范(DOCTYPE、视口设置、字体引入等)和设计系统约束(配色方案、间距比例等)。
组件级提示模板:根据节点类型动态选择,如导航栏提示包含"确保子项水平排列"和"活动状态高亮"等细节要求。
用户指令融合:通过特殊分隔符
=识别追加指令,并将其注入对应组件的生成上下文。
生成过程采用约束采样策略,确保输出符合HTML/CSS语法规范,并通过AST(抽象语法树)验证器进行即时校验,避免无效代码。
4. 图像内容还原技术
针对设计图中的真实图片(如产品照片、背景图),ScreenCoder开发了基于匈牙利算法的匹配系统:
对原始截图运行UIED检测,获取所有潜在图像区域。
计算生成代码中占位符与检测区域的CIoU(综合交并比)和仿射变换代价。
通过匈牙利算法求解最优一对一匹配,自动替换占位符为
<img src="data:image/png;base64,...">格式的真实图像数据。
该技术使生成页面的视觉保真度提升42%,大幅减少开发者的手动调整工作。
5. 训练与优化策略
ScreenCoder的双阶段训练机制包含以下创新:
监督微调(SFT):使用50K自动生成的图像-代码对训练Qwen-VL,损失函数结合视觉定位准确率(检测mAP)和代码语法正确率。
强化学习(RL):设计复合奖励函数: $$R = α·Block + β·Text + γ·Pos + δ·Color $$ 其中Block为组件区域匹配度,Text为Dice文本相似度,Pos为中心点对齐度,Color为色彩直方图相似度。
课程学习:按布局复杂度分级训练样本,从简单卡片逐步过渡到多层级仪表盘界面,加速模型收敛。
应用场景
ScreenCoder作为通用型前端自动化工具,其应用价值已在实际开发场景中得到验证,主要适用于以下六类典型用例:
1. 设计稿转代码
核心价值:消除设计师与开发者间的沟通鸿沟。当设计师提供Figma/Sketch等工具输出的视觉稿后,开发者可直接将其导入ScreenCoder,秒级生成可用代码,避免传统手动切图、标注的繁琐流程。某电商平台实测显示,采用该工具后landing page开发周期从3天缩短至2小时,且还原度达95%以上。
操作流程:
导出设计稿为PNG或PDF格式
上传至ScreenCoder Web界面或CLI工具
获取完整HTML/CSS代码及资源文件包
在生成代码基础上进行业务逻辑开发
2. 原型快速迭代
核心价值:加速产品概念验证。产品经理可用纸面草图或白板照片作为输入,立即获得可交互的HTML原型,支持实时修改-预览循环,比传统线框图工具(如Balsamiq)效率提升5倍。特别适用于创业团队在资源有限情况下快速验证UI方案。
典型指令流:
初始输入:手绘移动端APP首页草图 → 生成基础代码 追加指令:"=将底部标签栏改为5个图标" → 更新代码 追加指令:"=主色调改为#4285F4" → 最终代码
3. 遗留界面现代化
核心价值:低成本实现UI焕新。针对老旧系统界面截图,ScreenCoder可生成符合现代Web标准(HTML5/CSS3)的代码,同时保持功能一致性。某金融机构使用该工具将90年代VB6界面迁移至Web,开发成本仅为传统重写的1/10。
技术要点:
自动识别旧版控件(如下拉列表、单选框)并映射为等效HTML组件
保留原有布局结构但应用响应式设计改进
输出可访问性合规(WAI-ARIA)的标记
4. 多平台适配
核心价值:一次设计多端发布。通过调整生成参数,同一设计源可输出分别针对桌面、移动和平板的差异化代码,自动处理设备特定的布局调整(如移动端隐藏侧边栏)。某内容管理系统(CMS)提供商利用此功能将维护成本降低60%。
生成选项示例:
screen_coder generate input.png \ --platform=desktop \ # 或mobile/tablet --framework=tailwind \ # 或bootstrap/material --rtl=true # 支持从右到左语言
5. 教育辅助工具
核心价值:可视化前端教学。编程新手可通过修改生成代码观察视觉效果变化,直观理解HTML/CSS的盒模型、布局模式等抽象概念。教育机构反馈,结合ScreenCoder的课程使学生掌握Flexbox的时间缩短40%。
教学用例:
展示简单界面(如名片)的生成代码
指导学生修改padding/color等属性
对比修改前后渲染差异
逐步引入复杂布局(Grid)概念
6. 自动化测试素材生成
核心价值:丰富UI测试场景。QA工程师可描述虚构界面(如"包含错误提示的登录表单"),由ScreenCoder生成多样化测试页面,提升测试覆盖率20%以上。特别适用于视觉回归测试(Visual Regression Testing)的基准图像创建。
自动化集成:
def generate_test_page(description): image = text_to_image(description) # 使用扩散模型生成虚构UI code = screen_coder.generate(image) deploy_to_staging(code) run_visual_test()
相关链接
开源仓库: https://github.com/leigest519/ScreenCoder
Hugging Face Spaces: https://huggingface.co/spaces/leigest/ScreenCoder-Demo
论文地址:http://arxiv.org/abs/2507.22827
总结
ScreenCoder作为视觉到代码生成领域的突破性框架,通过创新的模块化多智能体架构成功解决了UI自动化开发中的核心挑战——如何在保持生成代码质量的同时,确保视觉设计的精准还原。项目将复杂的UI理解任务分解为定位、规划、生成三个专业阶段,每个阶段由针对性优化的智能体负责,结合领域特定的前端工程知识和强化学习优化策略,最终实现了超越商业模型的布局准确率(组件匹配0.755)和视觉保真度(CLIP相似度0.82)。其开箱即用的特性(支持直接生成生产级代码)和灵活的交互能力(自然语言指令修改)使工具在实际开发场景中能立即创造价值,实测减少前端重复工作70%。开源生态的完善(包含代码、模型、数据集)和模块化设计也为社区扩展和商业应用奠定了坚实基础,标志着前端开发自动化迈向新的成熟阶段。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/screencoder.html





















