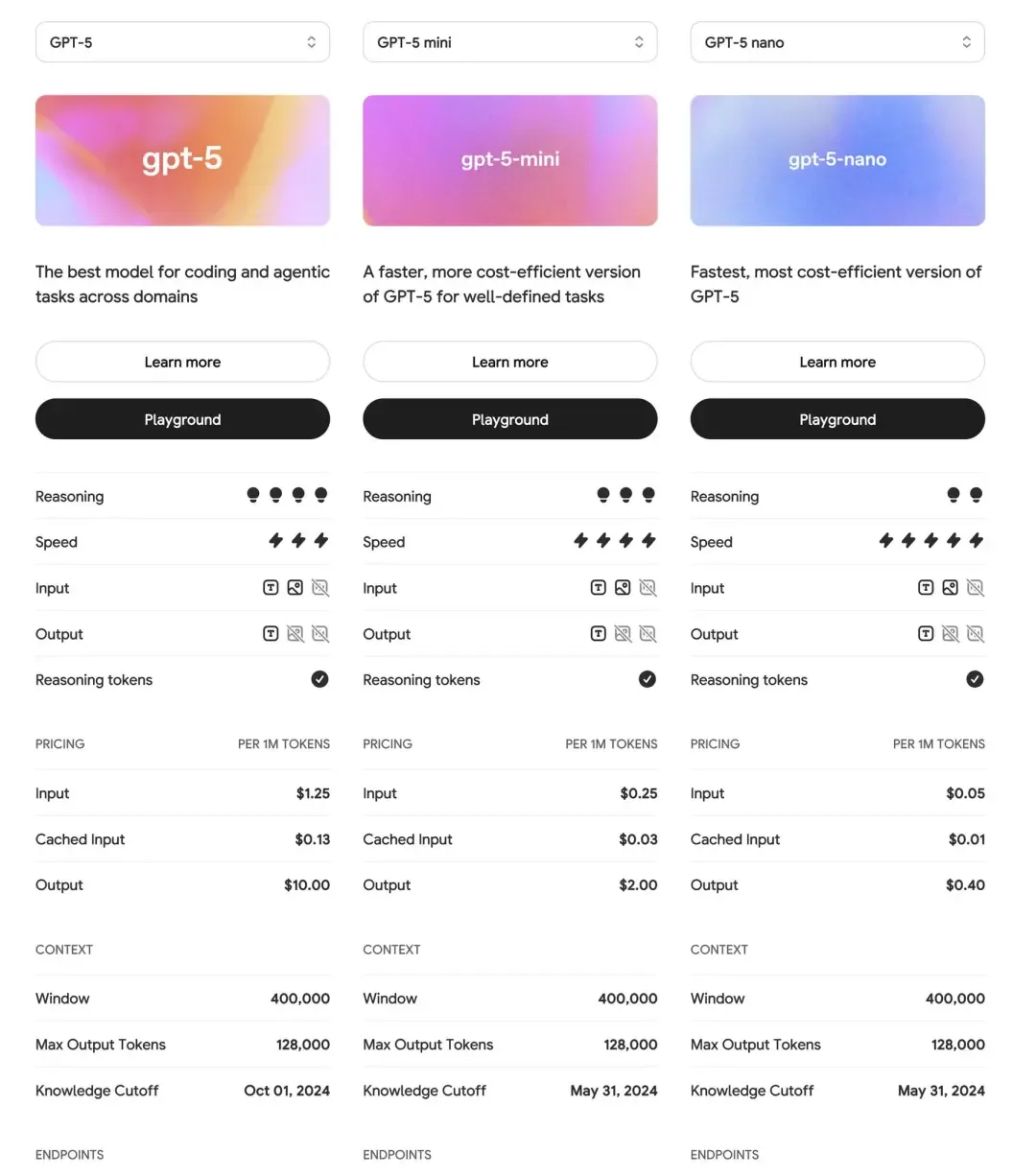
2025年8月8日,OpenAI正式推出划时代的GPT-5系列模型,通过四款定位精准的版本组合,将博士级AI能力带入从消费电子到企业系统的全场景。
北京时间2025年8月8日凌晨,OpenAI在全球瞩目下正式发布了第五代大语言模型GPT-5。与以往“单一旗舰模型”策略不同,此次OpenAI创新性地推出四款不同规格的版本:GPT-5标准版、GPT-5 Mini、GPT-5 Nano和GPT-5 Chat,形成覆盖多场景的完整产品矩阵。
这一策略革命性地解决了AI领域长期存在的“能力与成本不可兼得”的困境——用户既可选择顶级智能处理科研难题,也能以极低成本部署高频对话服务。
技术架构上,全系列基于统一Universal Transformer架构,支持最高40万token上下文输入和12.8万token输出,同时通过稀疏激活机制(Mixture of Experts)在1.8万亿总参数规模下保持推理效率,实际运行时仅激活1-2%参数(约200-300亿)。

01 旗舰王者:GPT-5标准版解析
作为整个系列的旗舰型号,GPT-5标准版代表了OpenAI当前最高技术水准。该模型拥有1.8万亿参数总量,通过专家混合架构(MoE),实际推理时动态激活200-300亿参数,在保持超强能力的同时显著优化计算效率。
在核心性能指标上,GPT-5展现出革命性的突破:
编程能力:在SWE-bench代码测试中达到74.9%准确率,在Aider Polyglot跨语言编辑测试中高达88%
数学推理:竞争性数学测试AIME 2025得分94.6%,GSM8K数学问题解决准确率98.3%
事实准确性:幻觉率比GPT-4o降低45%,启用深度思考模式后进一步降低80%
技术规格方面,标准版支持高达40万token上下文窗口,相当于超过900页文本的解析能力,同时输出长度可达128K token。这一容量使其能够处理整本专著、大型代码库或多年度财报数据。
核心使用场景聚焦高价值复杂任务:
科研分析与学术研究:自动解析跨多篇论文的研究数据,生成综述报告
金融建模与量化策略开发:输入“//写个量化交易策略”,直接输出完整Python代码+单元测试
法律文件分析:同时处理数百页合同文本,识别潜在风险条款
端到端应用构建:根据模糊需求描述生成完整可运行的Web应用或游戏
定价策略上,标准版定位高端:输入每百万token 1.25美元,输出每百万token 10美元。OpenAI同时提供token缓存优惠——重复内容调用可享90%折扣。
02 轻量之选:GPT-5 Mini详解
GPT-5 Mini作为轻量级选手,在性能与成本间取得卓越平衡。保留了标准版约80%的核心能力,但成本降低60%以上,成为中小企业及个人开发者的理想选择。
技术规格上,Mini版同样支持40万token上下文窗口和128K输出,但模型规模有所精简。其知识截止日期为2024年5月30日,略早于标准版的2024年9月30日。在实际响应速度上,Mini版比标准版快约40%,特别适合实时交互场景。
价格体系极具竞争力:输入每百万token仅0.25美元,输出每百万token 2美元,不到标准版的四分之一。这一价格策略使中等规模应用的大范围部署成为可能。
最佳应用场景覆盖日常商业需求:
企业自动化流程:客户邮件自动分类与响应生成,报告数据提取
内容创作支持:营销文案批量生成,社交媒体内容规划
中等复杂度数据分析:销售趋势解读,用户反馈情感分析
教育辅助工具:作业批改,个性化学习材料生成
在API调用中,开发者可通过Verbosity参数(high/medium/low)精确控制Mini版的输出详细程度,避免冗余信息。当标准版达到使用限额时,系统会自动无缝切换至Mini版,保障服务连续性。
03 极致高效:GPT-5 Nano技术剖析
GPT-5 Nano是系列中体积最小、速度最快、成本最低的成员,专为高频交互和边缘计算场景优化。其设计哲学是“以最小资源满足最大量级请求”。
性能表现上,Nano版响应延迟低于0.5秒,几乎达到人类对话的自然节奏。虽然处理复杂任务能力有限,但在专精小任务场景中效率惊人。支持上下文长度与系列一致(40万token输入/128K输出),但实际应用中更适合短文本交互。
定价革命性突破:输入每百万token仅0.05美元,输出每百万token 0.40美元,成本仅为前代GPT-4o的1/20。这一价格结构使AI普惠化真正成为现实。
核心部署场景包括:
高并发客服机器人:处理简单咨询、订单状态查询、FAQ应答
智能设备本地部署:在手机、汽车信息娱乐系统等边缘设备运行
实时交互应用:语音助手后台,游戏NPC对话生成
大规模数据预处理:日志分析,基础数据清洗与分类
在资源受限环境中,Nano版展现出卓越适应性。测试显示,其可在16GB显存的消费级显卡上流畅运行,大幅降低AI应用部署门槛。开发者通过Allowed Tools参数可精确限制其可调用工具范围,确保安全稳定运行。
04 对话专家:GPT-5 Chat专版揭秘
GPT-5 Chat版是系列中专为对话场景优化的成员,基于标准版同等技术架构,但强化了上下文记忆与个性化交互能力。
该版本核心优势在于对话连贯性与个性化服务:
长期偏好记忆:记住用户饮食禁忌、沟通风格等个性化设置
多轮对话优化:自动维持上下文一致性,减少重复确认
情感智能响应:检测用户情绪状态并调整回应方式
个性化知识管理:跨会话积累用户特定领域知识
在技术实现上,Chat版采用对话专用路由机制,能自动识别用户意图是简单查询还是深度讨论,并动态切换响应模式。例如当用户询问“本季销售为何下滑?”这类开放性问题时,会自动激活深度推理模块,分解经济趋势、CRM数据等多重因素,而非简单表层回答。
典型应用场景聚焦人机对话:
智能客服中心:提供类人对话体验,降低人工客服负担
个性化健康顾问:跟踪用户健康数据,提供定制建议
教育辅导助手:根据学生学习风格调整教学方法
心理支持聊天机器人:识别情绪变化并提供适当回应
企业应用中,Chat版可连接Gmail与Google Calendar(Pro专属功能),实现“自动提醒未回复邮件”和“结合行程做个性化建议”等高级功能。在安全策略上,采用创新的“安全补全”机制,在遵守安全边界的前提下最大化提供有价值信息。
05 四维对比:版本差异与选型指南
为清晰展现四个版本的核心差异,以下从技术规格、性能表现、成本和应用领域进行系统对比:
规格与性能
| 维度 | GPT-5标准版 | GPT-5 Mini | GPT-5 Nano | GPT-5 Chat |
|---|---|---|---|---|
| 参数规模 | 1.8万亿(激活200-300亿) | 未公开(标准版80%能力) | 极简优化 | 同标准版 |
| 上下文长度 | 400K token | 400K token | 400K token | 400K token |
| 最大输出 | 128K token | 128K token | 128K token | 128K token |
| 响应时间 | 2-5秒(复杂任务) | 1-3秒 | <0.5秒 | 1-4秒(视对话复杂度) |
| 编程能力(SWE-bench) | 74.9% | ≈60% | 基础支持 | 同标准版 |
经济性与适用场景
| 维度 | GPT-5标准版 | GPT-5 Mini | GPT-5 Nano | GPT-5 Chat |
|---|---|---|---|---|
| 输入成本($/百万token) | 1.25 | 0.25 | 0.05 | 同标准版 |
| 输出成本($/百万token) | 10.00 | 2.00 | 0.40 | 同标准版 |
| 最佳应用领域 | 科研/金融分析/复杂系统开发 | 中小企业自动化/教育辅助 | 高频客服/边缘设备 | 对话系统/个性化服务 |
| 实名认证要求 | 必需 | 必需 | 必需 | 必需 |
选型决策关键考量因素:
任务复杂度:涉及多步推理选标准版,简单问答选Nano
预算限制:高吞吐量场景首选Nano,高价值任务投资标准版
延迟敏感度:实时交互必须Nano,异步处理可考虑Mini
个性化需求:长期服务用户优先Chat版
测试数据显示,混合使用多版本可优化总体拥有成本40%以上——例如将95%的简单请求路由至Nano,仅5%复杂任务使用标准版。
OpenAI的GPT-5系列通过四款精准定位的版本,实现了AI能力与成本结构的梯度覆盖。标准版以博士级智能攻克科研与金融堡垒;Mini版以平衡设计服务企业日常;Nano版以极致效率赋能高频场景;Chat版以对话专精重塑人机交互。
这种分层策略背后是稀疏激活技术的成熟应用——在保持1.8万亿参数潜力的同时,通过动态激活少量专家网络(约1-2%)实现高效推理。而全系统统一的400K上下文窗口,则确保从简单问答到专著分析的一致体验。
随着GPT-5四剑客全面开放,从16GB显卡的开发者笔记本到企业级智能体平台,都获得了匹配其需求的AI能力。这标志着大模型应用正式告别“一刀切”时代,进入场景驱动、成本感知的精细化发展阶段。
本文由@zhanid 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/dnzs/5283.html


























