随着计算机图形学和人工智能技术的飞速发展,人物图像动画在影视制作、游戏开发、虚拟现实等领域的应用越来越广泛。然而,传统的人物图像动画方法往往需要依赖大量的密集输入,如深度图、光流场等,这不仅增加了数据获取的难度,也限制了动画生成的灵活性和通用性。为了克服这些挑战,研究人员提出了一种新的可控人体图像动画方法——DisPose。

DisPose是什么
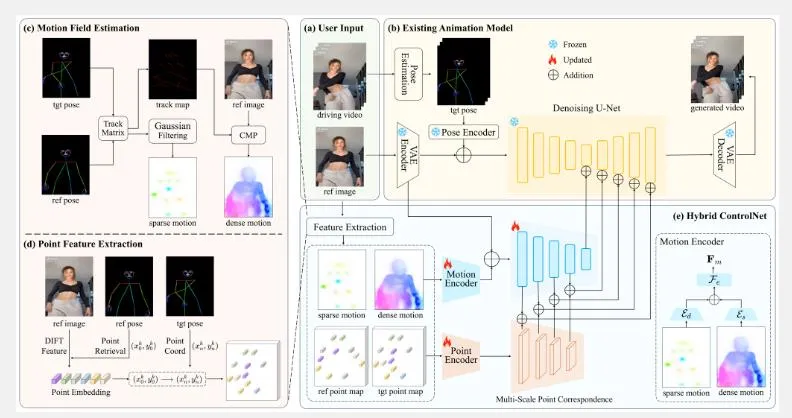
DisPose是一种基于稀疏和密集运动场估计、关键点特征提取和混合ControlNet的可控人体图像动画方法。它由北京大学、中国科学技术大学、清华大学和香港科技大学联合推出,旨在提高人物图像动画的质量和灵活性。DisPose通过从骨骼姿态和参考图像中提取有效的控制信号,生成密集运动场,并保持对不同体型的泛化能力。其核心在于将姿态控制分解为运动场引导和关键点对应,从而在无需额外密集输入的情况下,显著提升动画的生成质量和一致性。
功能特色
运动场引导
DisPose能够从骨骼姿态生成密集运动场,提供区域级的密集引导,增强视频生成中的动作一致性。这种运动场引导不仅考虑了全局的运动趋势,还关注了局部的运动细节,从而使得生成的动画更加自然流畅。
关键点对应
DisPose通过提取与参考图像中姿态关键点对应的扩散特征,将扩散特征转移到目标姿态,保持身份信息的一致性。这种关键点对应方法能够准确地捕捉人物的姿态变化,同时保持人物的身份特征不变,从而提高了动画的真实感和可信度。
即插即用模块
DisPose还包含一个即插即用的混合ControlNet模块,能够无缝集成到现有的人物图像动画模型中,改善生成视频的质量和一致性。这种即插即用模块的设计使得DisPose可以轻松地与其他动画模型结合使用,提高了其应用的灵活性和广泛性。
无需额外密集输入
DisPose在不依赖于额外密集输入(如深度图、光流场等)的情况下工作,减少了对参考角色和驱动视频之间身体形状差异的敏感性。这使得DisPose更加适用于实际应用中的复杂场景和多样化需求。
技术细节
稀疏和密集运动场估计
DisPose基于稀疏和密集运动场估计来生成动画控制信号。首先,它使用DWpose估计骨骼姿态,并将其表示为轨迹图。然后,它利用条件运动传播(CMP)基于稀疏运动场和参考图像预测密集运动场。这种运动场估计方法结合了稀疏和密集运动场的优点,能够提供更细致的运动信号。
关键点特征提取
DisPose使用预训练的图像扩散模型提取参考图像的DIFT特征,并将这些特征与关键点对应起来,形成关键点特征图。这些关键点特征图能够准确地捕捉人物的姿态变化和身份信息,为后续的动画生成提供重要的控制信号。
混合ControlNet
DisPose设计了混合ControlNet来无缝集成运动场引导和关键点对应。混合ControlNet在训练期间进行更新,以便将这两种控制信号有效地注入到潜在的视频扩散模型中。这种设计使得DisPose能够生成准确的人物图像动画,同时保持生成视频的质量和一致性。
特征融合与控制信号集成
DisPose基于特征融合层将稀疏和密集运动特征结合起来,生成最终的运动场引导信号。然后,它将运动场引导和关键点对应作为额外的控制信号,注入到潜在的视频扩散模型中,以生成最终的人物图像动画。这种特征融合与控制信号集成的方法使得DisPose能够生成高质量、高一致性的动画视频。
应用场景
影视制作
DisPose可以用于影视制作中的人物图像动画生成。通过将演员的表演捕捉为骨骼姿态和参考图像,DisPose可以生成高质量、高一致性的动画视频。这不仅可以减少特效制作的成本和时间,还可以提高影片的真实感和视觉冲击力。
游戏开发
DisPose也可以用于游戏开发中的人物图像动画生成。通过将游戏角色的动作捕捉为骨骼姿态和参考图像,DisPose可以生成流畅、自然的动画效果。这不仅可以提高游戏的视觉体验,还可以增加游戏的互动性和趣味性。
虚拟现实
在虚拟现实领域,DisPose可以用于生成逼真的虚拟人物动画。通过将用户的动作捕捉为骨骼姿态和参考图像,DisPose可以生成与用户动作同步的虚拟人物动画。这不仅可以提高虚拟现实的沉浸感和交互性,还可以增加虚拟环境的真实感和可信度。
动画制作
DisPose还可以用于动画制作中的人物图像动画生成。通过将动画师绘制的角色动作捕捉为骨骼姿态和参考图像,DisPose可以生成高质量的动画视频。这不仅可以减少动画制作的时间和成本,还可以提高动画的真实感和表现力。

总结
DisPose是一种基于稀疏和密集运动场估计、关键点特征提取和混合ControlNet的可控人体图像动画方法。它通过从骨骼姿态和参考图像中提取有效的控制信号,生成密集运动场,并保持对不同体型的泛化能力。DisPose的核心在于将姿态控制分解为运动场引导和关键点对应,从而在无需额外密集输入的情况下,显著提升动画的生成质量和一致性。DisPose具有运动场引导、关键点对应、即插即用模块和无需额外密集输入等功能特色,适用于影视制作、游戏开发、虚拟现实和动画制作等多个领域。通过相关官方链接,可以获取更多关于DisPose的信息和资源。DisPose的推出为人物图像动画领域带来了新的发展机遇和挑战,相信在未来的发展中将发挥越来越重要的作用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2788.html

开源的一款融合全景视频生成与3D重建的统一框架")
























