Loopy是什么
Loopy是由字节跳动和浙江大学联合开发的一款基于音频驱动的AI视频生成模型。它能够将静态照片或图像转化为动态视频,使照片中的人物能够根据输入的音频文件进行面部表情和头部动作的同步,生成自然且逼真的动态效果。Loopy不仅支持声音与画面的完美匹配,还能将表情与情绪融入虚拟角色的互动中,为用户提供了更加真实的体验。
功能特色
1. 音频驱动的动态视频生成
Loopy的核心功能在于其能够根据音频文件自动生成与之同步的动态视频。用户只需提供一张图片和一段音频,Loopy就能分析音频信号中的音调、语气和情感等信息,并将这些信息转化为视觉表现。这种音频驱动的方式使得视频生成过程更加自动化和智能化,无需人工进行繁琐的动画制作。
2. 面部表情和头部动作的同步
Loopy能够生成自然且逼真的面部表情和头部动作,使照片中的人物仿佛在说话或进行其他动作。它不仅能够准确地同步音频和口型,还能捕捉到细微的表情变化,如抬眉、吸气、憋嘴停顿、叹气等,使生成的视频更加生动和真实。
3. 支持多种视觉和音频风格
Loopy支持多种视觉和音频风格,用户可以根据需要选择适合的风格来生成视频。无论是古风画像、粘土风格、油画风格还是3D素材,Loopy都能表现出色。同时,它还支持多种音频风格,如柔和、高昂等,使生成的视频更加多样化和个性化。
4. 高度优化的性能
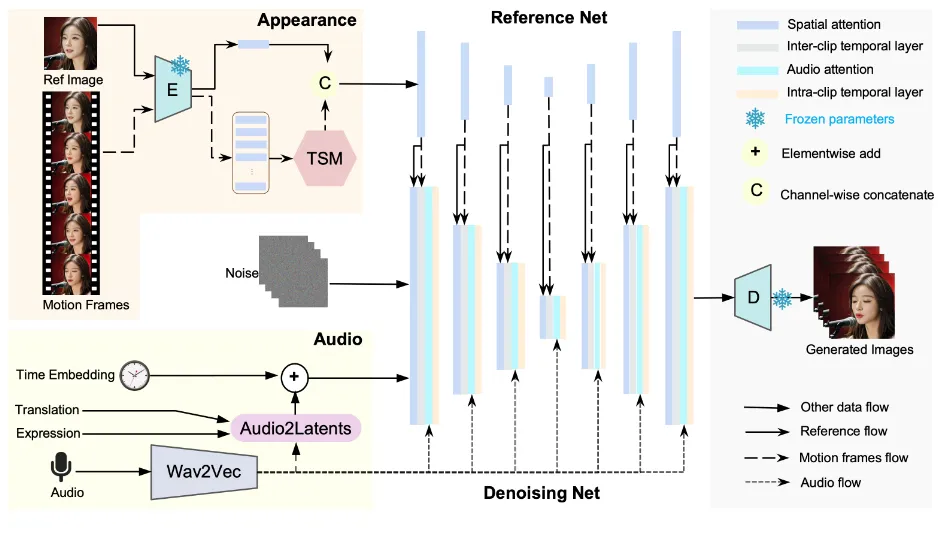
Loopy采用了先进的扩散模型技术,通过逐步引入噪声并学习逆向过程来生成视频数据。这种技术使得Loopy能够在保证生成视频质量的同时,提高生成速度和效率。此外,Loopy还设计了跨片段及片段内部的时间模块,使模型能够理解并利用长期信息,从而生成更自然且连贯的动作。
技术细节
1. 扩散模型技术
Loopy采用了Diffusion视频生成框架,这是一种基于噪声的生成模型。它通过在训练过程中逐步引入噪声到数据中,并在推理过程中逐步去除噪声来生成高质量的视频数据。这种技术使得Loopy能够在没有额外空间信号或条件的情况下,生成自然流畅的动作。
2. 跨片段及片段内部的时间模块
Loopy设计了跨片段及片段内部的时间模块,使模型能够理解并利用长期信息。跨片段时间模块能够捕捉跨时间片段的时序信息,而片段内部时间模块则能够捕捉单个片段内的时序信息。通过这两种时间模块的结合使用,Loopy能够生成更加自然且连贯的动作效果。
3. 音频到潜空间转换模块
Loopy还设计了一个名为audio to latents(A2L)的模块,用于增强音频和头部运动之间的关联关系。这个模块在训练过程中会随机选取音频、表情参数、运动参数中的一个,将其转化为motion latents,作为diffusion model的运动控制信号。在测试时,只需提供音频就能得到motion latents,从而实现音频驱动的视频生成。

应用场景
1. 社交媒体与娱乐
Loopy可以为社交媒体上的照片或视频增添动态效果,提升互动性和娱乐性。用户可以将自己的照片转化为动态视频,并与朋友们分享。此外,Loopy还可以用于制作搞笑视频、短视频等内容,丰富娱乐形式。
2. 电影与视频制作
在电影和视频制作领域,Loopy可以用于制作特效和动画。它可以将历史人物“复活”,创造生动的视觉体验。此外,Loopy还可以用于制作广告、MV等内容,为观众带来更加震撼的视觉享受。
3. 游戏开发
在游戏开发领域,Loopy可以为游戏中的非玩家角色(NPC)生成更真实自然的面部表情与动作。这不仅可以提升游戏的沉浸感,还可以增加游戏的趣味性和互动性。
4. 虚拟现实(VR)与增强现实(AR)
在VR或AR体验中,Loopy可以生成更加真实和沉浸式的虚拟角色。这不仅可以提升用户体验,还可以为教育、培训等领域提供新的解决方案。
5. 教育与培训
Loopy可以用于制作教育视频和培训材料。它可以通过模拟历史人物的演讲或重现科学实验过程等方式,使学习者更加直观地理解和掌握知识。此外,Loopy还可以用于制作在线课程和培训材料,为远程教育和培训提供支持。
6. 广告与营销
在广告与营销领域,Loopy可以创造引人注目的广告内容。它可以通过生成虚拟代言人、动态广告等方式,吸引消费者的注意力并提升品牌形象。此外,Loopy还可以用于制作互动广告和营销活动,增加消费者的参与感和忠诚度。

相关链接
Loopy项目主页:https://loopyavatar.github.io/
论文地址:https://loopyavatar.github.io/
总结
Loopy作为一款基于音频驱动的AI视频生成模型,具有强大的功能和广泛的应用场景。它能够根据音频文件自动生成与之同步的动态视频,使照片中的人物仿佛在说话或进行其他动作。Loopy不仅支持多种视觉和音频风格,还采用了先进的扩散模型技术和时间模块,保证了生成视频的质量和效率。在未来,随着技术的不断发展和应用场景的不断拓展,Loopy有望在更多领域发挥重要作用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3044.html


























