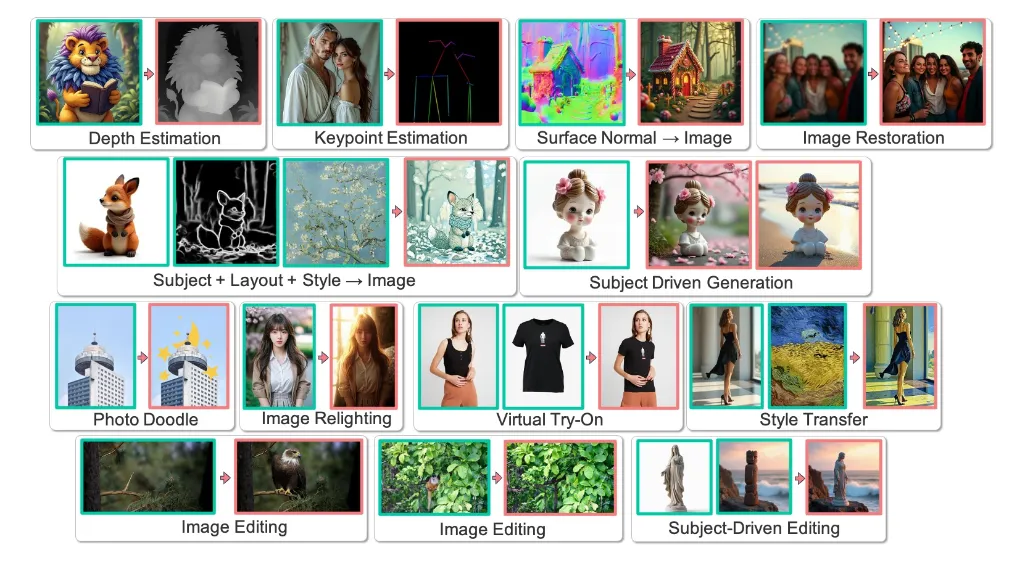
一、项目概述
VisualCloze 是一个通过视觉上下文学习实现通用图像生成的框架。该框架旨在解决现有图像生成模型在任务泛化方面的局限性,特别是当模型仅依赖语言指令时,难以适应不同的任务需求。VisualCloze 通过引入视觉上下文学习,使模型能够从少量的视觉示范中理解并执行任务,从而实现更为广泛和灵活的图像生成。
二、功能特色
统一多种任务:VisualCloze 能够将多种图像生成任务统一到一个步骤中,不仅生成目标图像,还能生成中间结果。这种统一的任务处理方式大大提高了图像生成的效率和灵活性。
支持逆向生成:除了从条件生成图像,VisualCloze 还支持逆向工程,即从目标图像中逆向推导出一组条件。这种逆向生成功能为图像分析和理解提供了新的视角和工具。
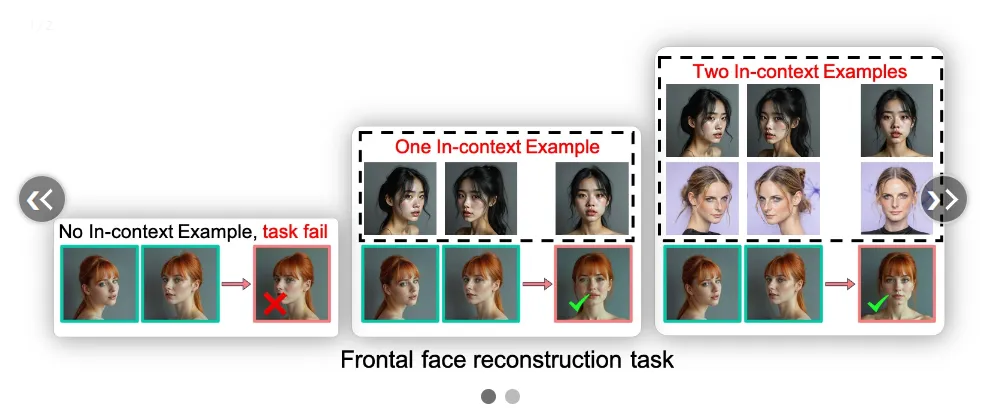
视觉上下文学习:与依赖语言指令的方法不同,VisualCloze 引入了视觉上下文学习,使模型能够从视觉示范中识别任务。这种方法有效地克服了语言指令带来的任务歧义和泛化能力弱的问题。
Graph200K 数据集:为了解决视觉任务分布的稀疏性问题,VisualCloze 引入了 Graph200K,一个基于图结构的多种相关任务的数据集。该数据集通过建立各种相互关联的任务,增强了任务密度和可迁移知识的学习。
利用预训练模型:VisualCloze 发现其统一的图像生成公式与图像填充共享一致的目标,因此能够利用预训练的填充模型的强大生成先验,而无需修改模型架构。这种利用预训练模型的方法大大提高了图像生成的效率和质量。
三、技术实现
VisualCloze 基于先进的通用填充模型 FLUX.1-Fill-dev 构建,通过拼接所有输入和输出图像到一个网格布局图像中,实现了任务的统一表示。为了解决上下文示例中不同纵横比图像组成的网格图像的难题,VisualCloze 利用了 FLUX.1-Fill-dev 中的 3D-RoPE 沿时间维度进行上下文拼接,有效地克服了这一问题,且没有引入任何明显的性能下降。
四、应用前景
VisualCloze 的出现为图像生成领域带来了新的思路和方法。其强大的任务泛化能力和灵活的图像生成方式使得它在多个领域都有广泛的应用前景,如图像编辑、风格迁移、图像恢复等。同时,VisualCloze 提出的视觉上下文学习和 Graph200K 数据集也为视觉模型的研究和应用提供了新的资源和工具。

五、相关链接
项目官网:https://visualcloze.github.io/
论文地址:https://arxiv.org/abs/2504.07960
在线演示:https://huggingface.co/spaces/VisualCloze/VisualCloze/
六、总结
VisualCloze 是一个通过视觉上下文学习实现通用图像生成的框架,它解决了现有图像生成模型在任务泛化方面的局限性,提供了强大的任务处理能力和灵活的图像生成方式。通过引入视觉上下文学习和 Graph200K 数据集,VisualCloze 为视觉模型的研究和应用提供了新的思路和工具。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3800.html


























