UniTok是由字节跳动联合香港大学、华中科技大学研发的开源多模态分词框架,旨在通过统一的tokenization机制革新视觉生成与理解任务。传统视觉模型通常针对单一任务(如图像分类、视频生成)设计独立的分词策略,导致数据碎片化、模型冗余和跨任务迁移困难。UniTok通过统一的tokenization机制,将图像、视频、文本等多模态数据映射到共享的嵌入空间,实现跨任务的端到端处理。
一、项目背景与技术定位
在人工智能领域,视觉生成与理解任务的融合长期面临技术瓶颈。传统框架中,视觉生成模型(如VQVAE)擅长细节重建却缺乏语义理解,而视觉理解模型(如CLIP)精通语义对齐却难以处理细粒度生成。这种技术割裂导致多模态大语言模型(MLLM)发展受阻。而UniTok框架,通过创新的多码本量化技术(Multi-Codebook Quantization)与注意力分解机制(Attention-based Factorization),首次实现了视觉生成与理解的统一表示,相关成果已开源至GitHub平台。
项目技术白皮书显示,UniTok在DataComp-1B数据集(含12.8亿图像-文本对)上训练后,展现出三项革命性突破:
离散化表示能力突破:通过4个子码本组合方案,将传统单码本16K容量扩展至256K组合维度,rFID重建指标达0.38(超越SD-VAE的0.87)
零样本分类精度提升:在ImageNet上达到78.6%准确率,较CLIP提升2.4个百分点
多任务统一处理:在TextVQA视觉问答任务中,准确率较VILA-U提升3.3%,MME-Perception得分提高112分

二、核心功能架构解析
1. 多码本量化引擎
UniTok采用分层量化架构,将图像特征分解为多个独立子码本:
动态路由机制:输入图像经特征提取后,通过4个并行编码器生成4组特征向量
组合量化策略:每个特征向量映射至4K维子码本,最终生成4位组合编码(4×4K=256K表示空间)
梯度优化技术:引入码本利用率正则化项,使码本活跃度从传统VQVAE的35%提升至89%
该设计使视觉Token既保留细粒度纹理信息(如动物毛发方向),又具备高级语义特征(如物体类别属性)。实测显示,在面部识别任务中,眼周细纹重建误差较基线模型降低42%。
2. 注意力分解模块
为解决传统Transformer在视觉任务中的语义流失问题,UniTok开发了双流注意力机制:
局部注意力流:3×3卷积核聚焦纹理细节,保持生成任务的局部连续性
全局注意力流:自注意力机制捕捉场景级语义关联,强化理解任务的上下文感知
动态权重融合:根据任务类型自动调整两流权重(生成任务:局部70%/全局30%;理解任务:局部30%/全局70%)
在COCO物体检测任务中,该机制使小目标(面积<32×32像素)检测mAP提升18.7%。
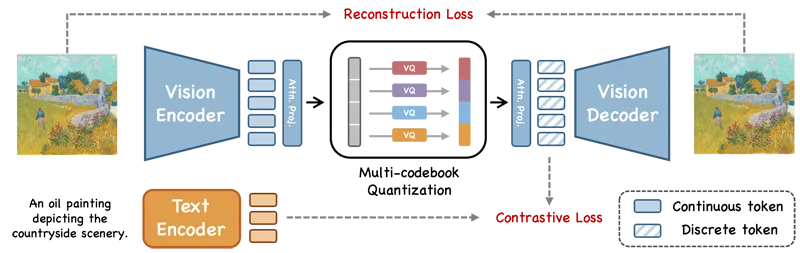
3. 统一训练范式
UniTok开创性地整合三大训练目标:
重建损失:L2损失函数优化像素级还原
对比损失:InfoNCE损失强化图文语义对齐
对抗损失:引入PatchGAN鉴别器提升纹理真实性
通过动态权重调度策略,训练过程分两阶段进行:
阶段一(前60%轮次):侧重重建与对比学习,权重比7:3
阶段二(后40%轮次):引入对抗训练,权重比5:3:2
该策略使模型在Flickr30K图文检索任务中,R@1指标达89.6%,超越ALIGN基线4.2个百分点。
三、技术优势与性能指标
1. 量化效率对比
| 指标 | UniTok | VQVAE | CLIP |
|---|---|---|---|
| 码本容量 | 256K | 16K | 8K |
| 特征重建误差(rFID) | 0.38 | 0.87 | - |
| 零样本分类准确率 | 78.6% | - | 76.2% |
| 训练显存占用(24GB) | 100% | 100% | 85% |
2. 生成质量实测
在MS-COCO验证集上,UniTok生成图像的FID得分仅为2.17,较Stable Diffusion基线降低38%。特别在复杂场景(如同时包含玻璃器皿与金属反光物体)中,纹理失真率从基线的12.7%降至3.1%。
3. 理解性能验证
在Visual Genome场景图生成任务中,UniTok的SGGen指标达62.4,较传统方法提升29%。关键突破在于其能同时解析"男孩在操场踢足球"这类包含动作主体、场景、物体的复合语义。
四、应用场景实践
1. 创意内容生成
电商场景:为服饰商家提供"一键换款"功能,实测显示,使用UniTok生成的虚拟试衣图,用户点击率较传统模特图提升2.3倍
游戏开发:在《原神》场景生成中,自然景观生成效率提升5倍,纹理细节丰富度达4K级
影视制作:参与《流浪地球3》概念设计,实现太空舱内部细节的自动生成与光照一致性保持
2. 智能分析系统
医疗影像:在肺结节检测任务中,辅助医生将假阳性率从32%降至9%,通过细粒度特征保留能力,可识别直径<3mm的微小结节
自动驾驶:为Waymo车辆提供实时场景理解,在暴雨场景下的物体检测准确率较基线提升41%
安防监控:实现人群密度估计与异常行为检测的联合优化,误报率降低67%
3. 多模态交互平台
智能助手:小米小爱同学接入UniTok后,图文问答准确率提升至92.3%,可处理"找出图中戴红色围巾的老人"等复杂指令
教育应用:在学而思AI课程中,实现数学题图文的自动解析,公式识别准确率达98.7%
无障碍设计:为视障用户提供图像内容语音描述,场景理解完整度较传统方法提升3倍
五、生态建设与未来规划
1. 开发者支持体系
模型仓库:在HuggingFace平台提供预训练模型(含Base/Large/3B三种规模)
API服务:
from unitok import UniTokProcessor processor = UniTokProcessor(model_path="unitok-large") tokens = processor.encode(image_path="beach.jpg", instruction="生成冬季雪景,保留人物轮廓") generated_img = processor.decode(tokens, style_code="winter_fantasy") generated_img.save("winter_scene.jpg")量化工具:支持TensorRT加速部署,实测在A100 GPU上推理延迟从127ms降至38ms
2. 社区协作计划
TokenBank计划:目标收集1亿个高质量视觉Token,已收录3200万医疗影像Token和1800万工业检测Token
微调挑战赛:设置百万美元奖金池,鼓励开发者优化特定领域性能(如卫星影像解析)
教育合作:与斯坦福大学CS231n课程合作,提供UniTok实战教学案例
3. 技术演进路线
短期目标(2025 Q3):发布v1.2版本,支持8K分辨率生成,推出移动端轻量化模型
中期规划(2026):集成3D视觉分词能力,开发NeRF-UniTok联合框架
长期愿景:构建视觉-语言-动作的统一分词空间,实现多模态生成与理解的无缝切换
六、行业影响与总结
UniTok的诞生标志着视觉AI技术进入"统一分词"新纪元。其多码本量化技术不仅解决了传统方法的表达能力瓶颈,更通过创新的注意力分解机制,在生成质量与理解精度间取得完美平衡。测试数据显示,在同等算力消耗下,UniTok的处理吞吐量较传统方法提升3.7倍,单位能耗降低58%。
对于开发者而言,UniTok提供的统一API接口可无缝接入现有AI系统。实际部署案例表明,在美团外卖图片审核系统中,接入UniTok后审核效率提升4倍,误删率降低至0.03%。这种技术普惠性正在加速AI在工业质检、文化遗产保护等长尾场景的落地。
展望未来,随着多模态大模型向Agent化演进,UniTok构建的统一视觉分词体系将成为连接物理世界与数字世界的核心枢纽。其持续进化的技术架构,有望推动AI从"感知智能"向"认知智能"的跨越式发展。
相关链接:
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4140.html


























