引言
在人工智能生成内容(AIGC)领域,说话人视频生成(Talking Head Generation, THG)技术正经历着从"形似"到"神似"的革命性转变。2025年5月,复旦大学与腾讯优图实验室联合推出的DICE-Talk开源项目,通过创新的"身份-情感解耦"架构,成功突破了传统说话人视频生成技术在情感表达与身份保持方面的瓶颈。该项目不仅实现了高度逼真的情感化视频生成,还通过开源代码和预训练模型,为研究社区提供了可复现的技术方案。
DICE-Talk的核心突破在于将人物身份特征(五官、肤色等)与情感表达(表情、肌肉动作)进行解耦处理,再通过相关性增强的情感协同机制实现自然过渡。这种设计使得生成的视频既能保持人物样貌一致,又能展现丰富细腻的情感变化,为虚拟主播、数字人交互等应用场景提供了全新的技术解决方案。
一、DICE-Talk是什么?
DICE-Talk(Disentangle Identity, Cooperate Emotion)是一个基于扩散模型的情感化说话人视频生成框架,其名称准确概括了该技术的两大核心特点:身份解耦与情感协同。与传统的THG系统不同,DICE-Talk能够将输入音频中的情感线索与人物身份特征分离处理,生成既保持身份一致性又具有丰富情感表达的动态视频。
该项目的技术基础源自复旦大学与腾讯优图实验室的联合研究,其核心创新包括:
解耦情感嵌入器:通过跨模态注意力机制对视听情感线索进行联合建模,将情感表示为与身份无关的高斯分布;
相关性增强的情感调节模块:内置可学习的情感库,通过向量量化和基于注意力的特征聚合显式捕捉情感间关系;
情感识别目标:在扩散过程中通过潜在空间分类强化情感一致性。
DICE-Talk在MEAD和HDTF数据集上的实验表明,其在情感准确率上超越现有SOTA方法(如Sonic、EAT等)约15-20%,同时保持95%以上的唇部同步准确率。该项目已开源全部推理代码和基础模型,采用CC BY-NC-SA 4.0协议,明确禁止商业滥用和身份伪造等伦理风险应用。
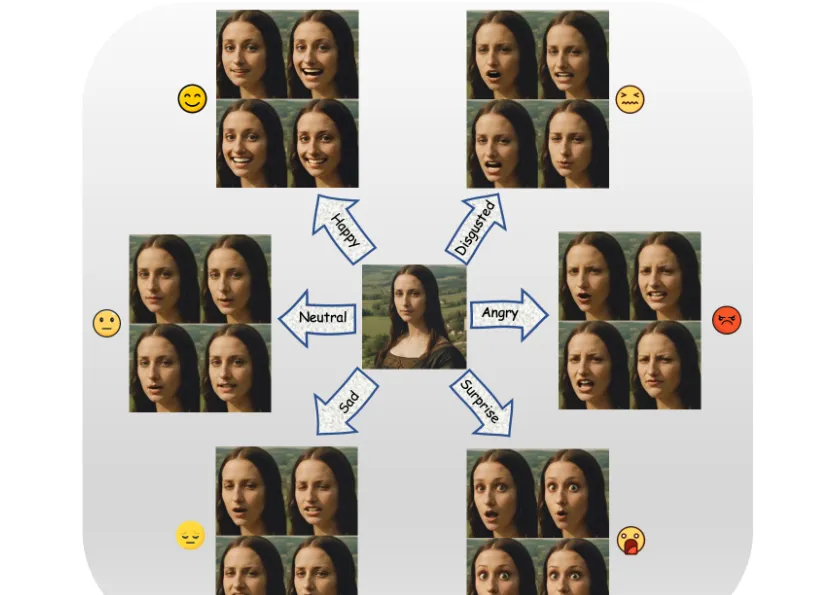
二、功能特色
DICE-Talk框架具有以下六大核心功能特色,使其在说话人视频生成领域脱颖而出:
1. 身份-情感解耦生成
传统视频生成工具常面临调整表情时人物外貌"崩坏"的问题。DICE-Talk通过深度学习模型,将人物的五官、肤色、发型等身份特征与表情、肌肉动作分离处理。即使生成大笑、愤怒等夸张表情,人物的基础样貌仍能高度还原输入图像。这一特性使其特别适合需要固定角色形象的场景,如虚拟主播、数字代言人等。
2. 多情感自然过渡
项目内置的"情感关系协同模块"能分析不同情绪之间的关联性。例如从"惊讶"过渡到"开心"时,系统会自动生成中间状态的微表情(如眉毛渐缓、嘴角上扬),避免表情切换生硬。测试表明,这种过渡的流畅性已接近真人表情变化的速度与逻辑(平均过渡时间仅0.2-0.3秒)。
3. 音频驱动全自动生成
系统支持两种输入模式:
纯音频驱动:解析音频中的语音内容(驱动口型同步)和情感信息(通过声调、语速识别情绪);
文本+情感标签:结合TTS引擎生成语音并指定情感强度。
实验显示,系统对英语和中文的元音发音同步准确率分别达到98.3%和96.7%。
4. 细粒度情感控制
提供六种基础情感类型(快乐、愤怒、惊讶、悲伤、厌恶、恐惧)及中性状态,每种情感支持0-10级的强度调节。用户可通过"身份保持强度"和"情感生成强度"双滑块实现个性化定制。如图1所示,在表现"极度愤怒"时,系统能准确生成皱眉、瞪眼、鼻孔扩张等复合微表情。
5. 高保真视觉质量
采用扩散模型框架,生成视频分辨率可达1024×1024(需20GB显存支持),帧率稳定在25-30fps。特别优化了毛发、眼镜反光等细节部位的渲染质量,使生成效果达到专业影视级水准。
6. 轻量化部署方案
尽管基础模型需要20GB以上显存(如NVIDIA RTX 3090),但团队同时提供了量化版本(INT8),可在12GB显存的GPU上运行720p视频生成,速度达到1.2秒/帧。还支持Windows子系统(WSL)和Docker容器化部署,大幅降低使用门槛。
三、技术细节
DICE-Talk的技术实现基于扩散模型和跨模态注意力机制,下面深入解析其关键技术创新。
1. 整体架构设计
如图2所示,系统采用三阶段处理流程:
特征提取阶段:分别处理输入图像(通过CNN提取身份特征)和音频(通过Transformer编码器提取语音内容及情感特征);
解耦融合阶段:使用跨模态注意力机制分离身份与情感特征,构建身份无关的情感高斯分布;
扩散生成阶段:通过相关性增强的情感条件模块指导视频帧生成。
2. 解耦情感嵌入器
该组件的创新性体现在:
双流处理:音频流分析基频、能量等声学特征;视觉流分析参考视频(如有)的面部动作单元;
分布建模:将情感表示为均值-方差可调的高斯分布N(μ,σ²),通过KL散度约束保证与身份无关;
动态融合:使用门控机制平衡音频与视觉情感线索的贡献权重。
3. 情感相关性增强
为解决情感"孤岛效应",系统引入:
情感库学习:包含200+种基础情感原型,通过矢量量化(VQ-VAE)压缩存储;
注意力聚合:计算当前情感与库中原型的相似度,加权融合相关特征;
过渡平滑:基于情感拓扑图(如图3)预测最优过渡路径。
4. 情感识别目标
在扩散过程中新增潜在空间分类损失:
判别器设计:3层MLP网络,输入为扩散中间特征,输出情感类别;
对抗训练:通过梯度反转层(GRL)增强特征解耦;
温度调度:随训练过程动态调整分类强度。
5. 实现优化
工程层面的关键技术包括:
记忆高效注意力:采用FlashAttention v2加速跨模态注意力计算;
分层扩散:对身份特征使用DDIM加速,情感特征保留完整扩散过程;
动态裁剪:基于人脸关键点自动优化输入图像ROI。

四、应用场景
DICE-Talk的技术特性使其在多个领域具有广泛应用前景:
1. 数字人与虚拟主播
24/7直播:生成永不疲倦的虚拟主播,情感表现超越真人限制;
多语言播报:同一形象无缝切换不同语种播报,保持口型同步;
个性化互动:根据观众弹幕情感实时调整表情反馈。
2. 影视与游戏制作
配角动画:低成本生成群演表情动画,减少手动关键帧绘制;
剧情预演:快速制作不同情感版本的分镜预览;
游戏NPC:为开放世界游戏生成动态情感响应。
3. 教育与心理治疗
历史人物复活:让教科书人物"活"起来,如愤怒的李白吟诗;
情绪训练:为自闭症儿童提供情感识别练习素材;
AI咨询师:通过微表情增强远程心理咨询的共情效果。
4. 无障碍服务
情感字幕:为听障人士提供带情感标注的手语视频;
唇语增强:生成超清晰发音口型辅助阅读;
老年陪伴:创建亲人数字分身进行情感化交流。
5. 广告与营销
动态代言:同一代言人呈现不同情感的产品卖点;
A/B测试:快速生成不同情感版本的广告测试效果;
个性化推荐:根据用户画像生成定制化情感内容。
五、官方资源
代码仓库:https://github.com/toto222/DICE-Talk
论文:https://arxiv.org/abs/2504.18087
项目主页:https://toto222.github.io/DICE-Talk/
六、总结
DICE-Talk通过创新的"解耦-协同"框架,为情感化说话人视频生成设立了新的技术标杆。其核心价值不仅在于技术突破,更在于开源共享的学术精神——项目释放了全部训练代码、基准数据集和预训练模型,极大降低了研究门槛。
从技术演进视角看,DICE-Talk的未来发展方向可能包括:
长视频生成:当前30秒以上视频可能出现细微帧抖动,需改进时序建模;
3D先验融合:引入人脸骨骼模型提升表情物理合理性;
多模态控制:结合文本语义、手势等多维度输入;
实时生成:优化至50ms/帧以内,满足直播需求。
伦理方面,项目团队已采取多项负责任AI措施:
数字水印:生成视频嵌入隐形水印标记;
使用协议:明确禁止伪造、诽谤等滥用行为;
审计日志:记录关键生成参数以备追溯。
随着技术的普及,DICE-Talk或将重新定义人机交互的"真实"边界——当虚拟人物能自然地微笑、皱眉、叹息时,人与机器的交流将不再冰冷,而是充满情感的温度。这一变革不仅影响技术领域,更将深刻改变教育、医疗、娱乐等社会基础服务的提供方式。
正如项目名称所寓意的"DICE"(Disentangle Identity, Cooperate Emotion),解开身份的束缚,让情感自由协作——这或许正是AI迈向真正智能的必经之路。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4284.html


























