一、3DTown是什么?
3DTown是由加州大学圣克鲁兹分校、哥伦比亚大学与Cybever AI联合开发的开源AI框架,专注于从单张俯视图生成高质量、连贯的3D城镇场景。其核心突破在于免训练(training-free)设计,直接利用预训练的3D对象生成器(如Trellis),通过区域化生成与空间感知修复技术,实现复杂场景的快速合成。传统方法需依赖多视角数据或人工建模,而3DTown仅需一张输入图像即可输出几何结构精细、纹理逼真的3D模型,显著降低了3D内容生成的门槛。
二、功能特色
免训练高效生成
无需额外3D数据训练或微调,直接复用预训练模型,节省90%以上的计算资源。多风格场景适配
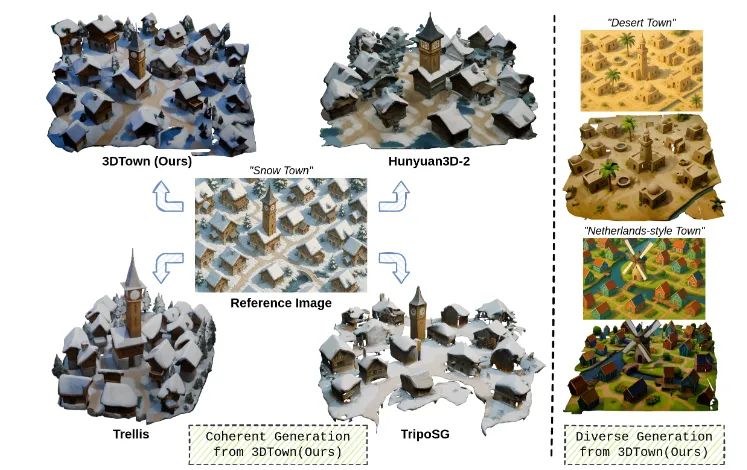
支持生成雪镇、沙漠小镇、荷兰风格城镇等多样化场景,且保持风格一致性。高精度几何与纹理
几何质量:人类评估显示,其几何细节得分比Trellis高37%,比TripoSG高55%。
纹理保真度:模型表面材质逼真,无重复贴图或扭曲现象。
全局连贯性
通过空间感知修复技术,确保生成的区域无缝拼接,避免布局“跑偏”或结构断裂。模块化灵活扩展
支持替换不同预训练生成器(如Trellis、Hunyuan3D-2),适应未来技术迭代。
三、技术细节
区域化生成策略
重叠区域分解:将输入图像划分为重叠子区域,分别生成高分辨率3D局部模型,解决全局生成的分辨率瓶颈。
独立潜在表示:每个区域通过预训练生成器输出结构化潜在编码(含位置索引与特征向量),确保局部对齐。
空间感知3D修复
粗略结构初始化:基于单目深度估计与地标提取构建场景空间先验,生成基础几何框架。
掩码矫正流(Masked Rectified Flow):填补区域间的几何缺失,同时保留已知结构的连续性,类似“3D瓦工”无缝拼接碎片。
两阶段生成流水线
阶段一(稀疏结构生成器):创建低密度点云框架,定义场景宏观布局。
阶段二(结构化潜在生成器):细化几何与纹理,输出完整潜在表示供解码。
关键算法优势
无监督融合:通过概率潜在空间融合区域生成结果,避免显式对齐计算。
动态掩码调整:修复过程中动态更新掩码区域,优先处理高置信度结构。
四、应用场景
游戏与影视开发
快速生成开放世界或电影背景,如《雪镇》场景仅需5分钟生成,成本降低80%。元宇宙与VR/AR
用户上传草图即可构建可交互的虚拟城镇,加速元宇宙内容生产。机器人仿真训练
为自动驾驶或服务机器人提供高保真训练环境,如模拟沙漠城镇中的导航任务。数字孪生与城市规划
基于卫星俯视图生成3D城市模型,辅助基础设施设计与灾害模拟。
五、相关链接
论文地址:https://arxiv.org/pdf/2505.15765
项目主页:https://eric-ai-lab.github.io/3dtown.github.io/
六、总结
3DTown通过“分解-生成-修复”的三步策略,实现了2D到3D场景生成的革命性突破。其免训练特性与模块化设计,使其在效率、质量与灵活性上远超传统方法(如Trellis、TripoSG)。当前局限包括对单物体生成器的依赖(可能导致局部“幻觉”)及初始结构估计的孔洞问题,未来可通过多视角数据融合或语义先验注入进一步优化。
作为3D内容生成的里程碑,3DTown为游戏、影视、元宇宙等领域提供了“草图即世界”的创作范式,预示个体用户也能成为3D内容的快速生产者。其开源计划将加速社区生态发展,推动AI驱动的3D创作进入普惠时代。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4379.html


























