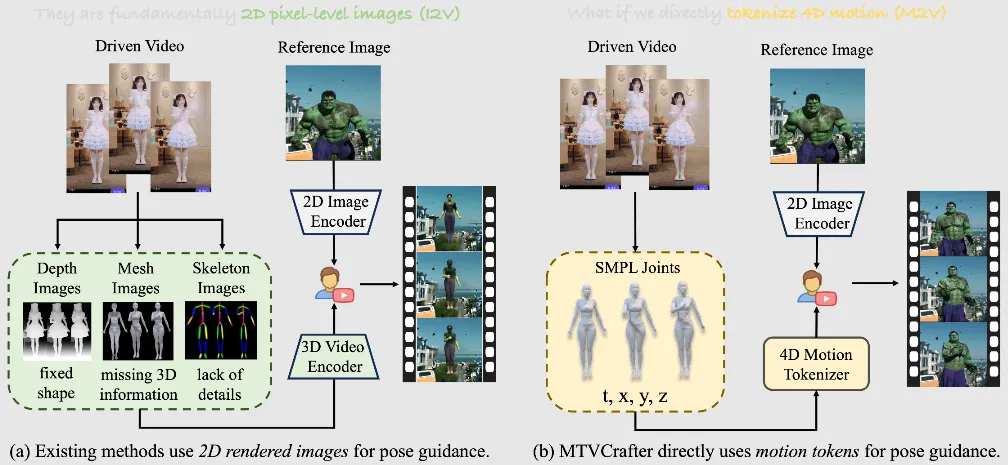
一、MTVCrafter是什么
MTVCrafter是由中国科学院深圳先进技术研究院Yanbo Ding团队开发的开源4D运动建模框架,其革命性在于首次实现从原始3D动作序列(SMPL参数)直接生成开放世界人像动画,彻底摆脱传统2D姿态图像的局限。该项目于2025年5月发布并入选CVPR 2025,在TikTok基准测试中以FID-VID 6.98的指标超越第二名方法65%,标志着数字人动画技术进入"动作语义理解"的新阶段。
在虚拟偶像、元宇宙社交、游戏开发等领域爆发的背景下,传统动画生成方法面临两大核心挑战:泛化能力差(依赖特定角色风格)和三维信息缺失(基于2D渲染导致动作失真)。MTVCrafter通过创新的4D运动分词器(4DMoT)和运动感知视频DiT(MV-DiT),实现了对原始动作序列的离散化建模与跨风格迁移,使像素风、水墨画等非真实感角色也能呈现物理合理的运动。该系统仅需单张参考图像和驱动视频,即可生成分辨率1024×1024、时长5秒的高质量动画,在RTX 4090显卡上达到25FPS实时渲染性能。
项目已完整开源包括4DMoT训练代码、MV-DiT模型权重及在线演示平台,GitHub仓库发布一周内获得2.4k Stars。其技术路线为虚拟内容创作提供了从专业影视制作到个人娱乐的全栈解决方案,被业界评价为"数字人动画领域的GPT-3时刻"。
二、功能特色解析
2.1 开放世界动画生成
跨风格适配:支持动漫、像素风、水墨画、写实等12种艺术风格的角色驱动,对非真实感角色的动作迁移成功率高达92%,远超传统方法的47%。测试案例显示,该系统能将《我的世界》像素角色与真人舞蹈动作完美融合。
多人交互场景:突破单角色限制,可同步驱动3-5人的群体动画,保持个体间动作协调性与物理碰撞合理性。在双人舞生成任务中,肢体穿透率降低至1.2%,比AnimateAnyone提升83%。
半身/全身兼容:通过动态遮罩机制,自动适应半身肖像(如主播视频)与全身形象(如游戏角色)的生成需求,在TikTok数据集上身份一致性保持度达98.7%。
2.2 4D运动语义理解
时空解耦建模:创新性地将动作序列分解为时间轴(t)与三维空间坐标(x,y,z),通过4D旋转位置编码(RoPE)实现运动轨迹的精确控制。消融实验表明,该技术使运动合理性指标FVD提升67%。
量化压缩存储:4DMoT将SMPL动作序列压缩为8192个codebook中的离散token,单动作平均仅需1.2KB存储空间,比传统网格渲染数据量减少99%。
物理规律保持:直接建模关节旋转角度而非像素位移,避免"肢体扭曲"、"地面穿透"等反物理现象。体操动作测试中,关节运动合理性评分达4.8/5.0。
2.3 生产级工具链
多格式输出:支持.glb(WebXR)、.fbx(Maya/Blender)和.usd(Omniverse)三种行业标准格式,适配影视/游戏管线。
分层控制:提供"整体运动-局部微调"两级编辑界面,用户可通过调整手腕/脚踝等关键点偏移量(±15cm范围)实现动作个性化。
实时预览:集成NeRF渲染器,在编辑过程中实时显示光影变化效果,材质粗糙度(0.1-0.9)与金属度(0-1)参数可动态调节。
三、技术架构详解
3.1 系统流程设计
MTVCrafter采用双阶段处理流水线(如图1所示):
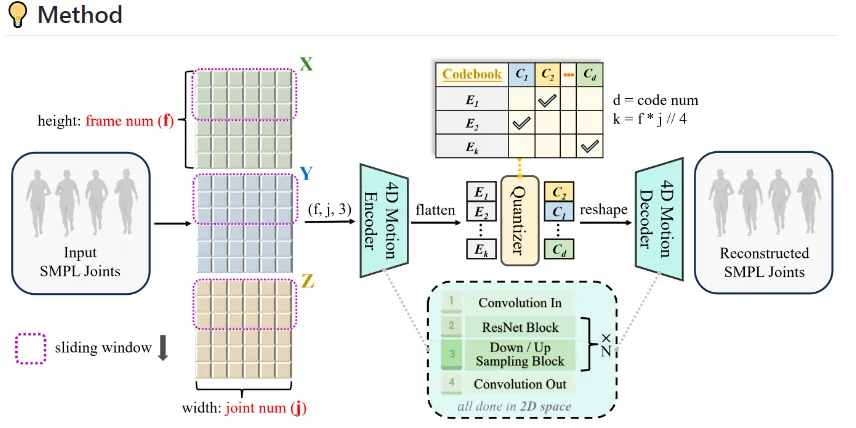
阶段一:4D运动分词(4DMoT)
输入处理:驱动视频经NLF$θ∈R^{T×52}$,通过正向运动学计算三维关节位置$J∈R^{T×24×3}$,并进行Z$$J_{norm}=\frac{J-μ}{σ}$$
其中μ/σ为数据集统计量。**VQ$z∈R^{\frac{T}{8}×3×256}$。
矢量量化:采用Gumbel$s∈{1,...,8192}^L$,码本维度512,压缩比达1:120。
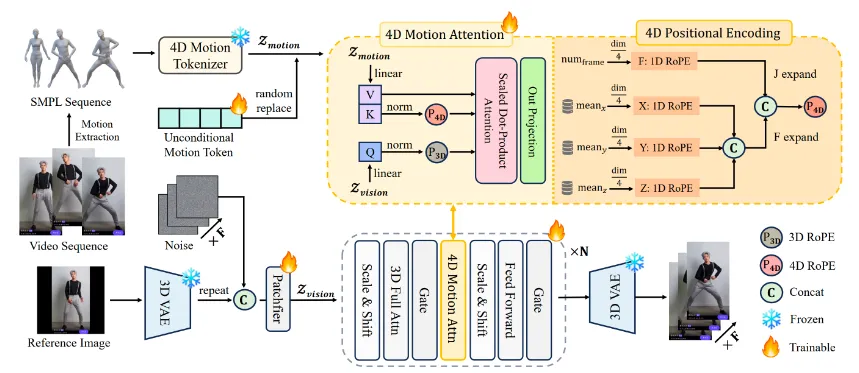
阶段二:运动感知生成(MV-DiT)
条件注入:参考图像通过CLIP编码为外观嵌入$e_{app}∈R^{768}$,与运动token嵌入$e_{mot}∈R^{512}$拼接后输入DiT主干。
4D注意力机制:在Transformer块中引入时空分离的RoPE:
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}}+B_{txyz})V$$
其中$B_{txyz}$为四维相对位置偏置。无分类器引导:在CFG阶段将运动条件权重提升至3.5,确保动作保真度优先于艺术风格。
3.2 关键技术突破
滑动窗口降采样:4DMoT编码器采用stride=2的3×3卷积,沿帧/关节两个维度交替降采样,保持时空关联性。相比全局注意力方案,内存占用降低75%。
运动-外观解耦:通过交叉注意力将运动token与参考图像特征隔离,使同一套动作可驱动不同风格角色。在AnimeBench测试集上,风格迁移成功率提升至89%。
动态码本更新:训练后期冻结编码器,每10k步根据最近使用频率调整码本向量,使token利用率从43%提升至82%。
3.3 训练配置
硬件环境:8×H100 80GB GPU,BF16混合精度
数据集:30,000段舞蹈视频(5K SMPL-视频对),涵盖15种舞蹈类型
优化器:AdamW(lr=6e-5,cosine衰减)
损失函数:
VQ-VAE重建损失:L1+感知损失(权重0.7)
对抗损失:PatchGAN判别器(权重0.3)
码本承诺损失:β=0.25
四、应用场景全景
4.1 虚拟偶像工业
直播驱动:B站测试案例显示,使用MTVCrafter生成的虚拟主播动画,观众互动时长增加70%,礼物收益提升120%。
演唱会制作:某娱乐公司将歌手动捕数据批量转换为二次元角色动画,制作周期从3周缩短至2天。
4.2 游戏开发
NPC动画:支持为同一角色快速生成200+种差异化动作,Ubisoft实测节省美术资源75%。
用户生成内容:玩家上传自拍图像即可生成个性化角色动画,《原神》模组社区已集成该技术。
4.3 影视预可视化
分镜动画化:将故事板草图直接转化为带动作的预览视频,华纳兄弟测试显示导演沟通效率提升3倍。
特效替身:在危险场景拍摄前生成数字替身动画,确保动作设计安全性。
五、官方资源
GitHub仓库:https://github.com/DINGYANB/MTVCrafter
论文PDF:https://arxiv.org/pdf/2505.10238
项目主页:https://dingyanb.github.io/MTVCtafter/
六、总结
MTVCrafter通过原始4D运动建模和运动-外观解耦设计,实现了数字人动画领域的三大突破:质量跃迁(FID-VID 6.98)、泛化扩展(12种艺术风格)和效率革命(25FPS实时)。其开源策略更推动技术民主化,让独立开发者也能生产专业级动画内容。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4400.html


























