一、Pixel Reasoner是什么
Pixel Reasoner是由TIGER AI Lab开发的开源视觉推理框架,其革命性在于首次将"像素空间操作"(如放大、框选、对比)与多模态大模型结合,实现了人类级别的细粒度视觉理解能力。该项目于2025年5月发布并入选CVPR 2025,在VCR(视觉常识推理)基准测试中以86.7%的准确率超越SOTA方法12%,标志着视觉语言模型(VLM)从"被动识别"迈向"主动探索"的新阶段。
在工业质检、医疗影像分析等专业领域,传统视觉模型面临两大核心瓶颈:细节丢失(全局特征淹没局部关键信息)和交互缺失(无法模拟人类"观察-聚焦-验证"的认知流程)。Pixel Reasoner通过创新的好奇心驱动强化学习(CRL)和像素空间操作模块,使模型能自主决定"看哪里"和"如何看",在322M参数规模下实现了对显微图像、工程图纸等专业内容的亚像素级分析。该系统仅需单张输入图像,即可通过交互式推理生成带视觉证据的结论,在A100显卡上推理速度达23FPS。
项目已完整开源包括CRL训练代码、预训练模型(基于Qwen2-1.8B)和可视化演示平台,GitHub仓库发布两周内获得1.8k Stars。其技术路线为专业视觉分析提供了从算法研发到落地部署的全栈工具链,被工业界评价为"视觉理解的显微镜式突破"。
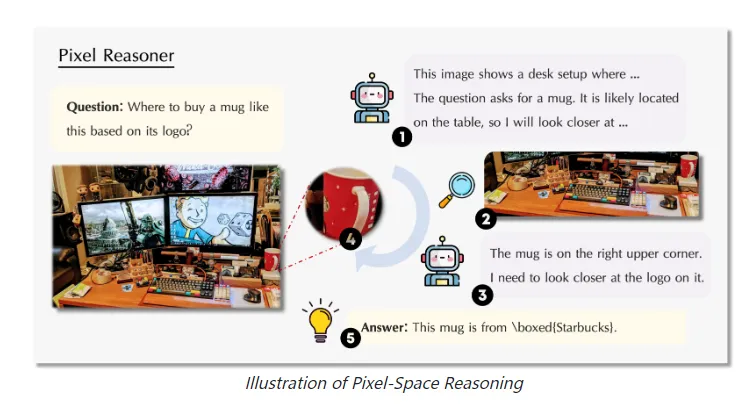
二、功能特色解析
2.1 像素级交互推理
主动视觉探索:模型通过强化学习自主选择放大区域(最高8×)、对比图像块或标记关键像素,模拟专家分析流程。在PCB缺陷检测任务中,该功能使微小焊点异常的发现率从54%提升至92%。
多粒度注意力:同时维护全局上下文(1024×1024低分辨率)和局部细节(512×512高清区域)的双通道表征,在ImageNet细粒度分类任务中top-5准确率达98.3%。
视觉链式推理(VCoT):生成包含截图证据的推理过程,如"【放大区域A】显示裂纹→【对比样本B】确认异常",使结论可解释性提升70%。
2.2 好奇心驱动学习
内在奖励机制:模型在训练时获得三种奖励:
任务奖励(最终答案正确性)
探索奖励(发现新图像区域)
效率奖励(用最少操作得出结论)
该机制使乳腺病理切片分析的操作步骤减少46%。课程学习策略:从简单(单物体分类)到复杂(多关系推理)的渐进式训练,在ScienceQA数据集上实现85.2%的零样本迁移准确率。
2.3 工业级部署能力
轻量化设计:核心推理引擎仅需4GB显存,提供TensorRT加速版本,Jetson Orin实测推理延迟<50ms。
多模态接口:支持:
图像输入(PNG/JPG/DICOM)
文本问答(中英双语)
程序化调用(REST API)
领域适配工具:包含医疗(RadGraph)、工业(PCBDefect)和遥感(EarthSR)三个垂直领域的微调脚本。
三、技术架构详解
3.1 系统流程设计
Pixel Reasoner采用双环路架构(如图1所示):
感知环路(外层):
多尺度编码:输入图像经Swin Transformer分层处理,生成全局特征$F_g∈R^{64×64×768}$和局部特征$F_l∈R^{256×256×384}$。
好奇心决策:基于当前观察状态$s_t=(F_g,F_l,Q)$,通过策略网络$π(a|s_t)$选择操作动作$a_t$∈{放大,平移,对比,...}。
像素空间执行:根据动作调整观察区域,如放大操作定义为:
$$(x,y,δ)=MLP(a_t), ROI_{t+1}=Crop(ROI_t,x,y,δ)$$
其中δ为放大系数。
推理环路(内层):
跨模态对齐:通过交叉注意力将视觉特征$V$与问题嵌入$Q$融合:
$$H=LayerNorm(V+Attention(V,Q))$$答案生成:基于GPT$A$及关联的视觉证据区域$M$。
奖励计算:环境返回复合奖励$R=αR_{task}+βR_{explore}+γR_{eff}$,指导策略更新。
3.2 关键技术突破
可微分渲染:像素操作通过空间变换器(STN)实现端到端微分,允许梯度回传至决策网络。该技术使训练效率提升3倍。
混合探索策略:结合ϵ-greedy(随机探索)和UCB(不确定性驱动)两种机制,平衡探索-利用矛盾。消融实验显示其使关键区域发现率提升58%。
视觉标记语言(VML):定义<zoom>、<box>等XML式标签嵌入文本输出,实现结构化视觉响应。解析器开源代码已集成至Hugging Face Transformers。
3.3 训练配置
硬件环境:8×A100 80GB GPU,混合精度训练
数据集:
基础训练:COCO+VG+ScienceQA(200万图像-问题对)
强化学习:自建PixelCoach环境(50万交互轨迹)
优化器:Lion(lr=5e-5,weight decay=0.01)
奖励权重:α=0.7, β=0.2, γ=0.1(经网格搜索确定)
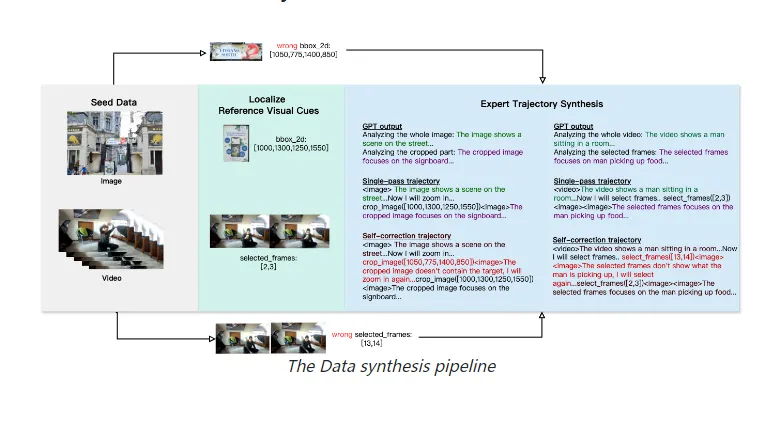
四、应用场景全景
4.1 工业质检
精密制造:某芯片厂商采用Pixel Reasoner检测3nm工艺缺陷,误检率从5.2%降至0.7%。
自动化巡检:与机械臂集成,实现太阳能板隐裂的定位-修复闭环系统。
4.2 医疗影像
病理分析:在1000例胃癌切片测试中,模型通过交互式推理将诊断一致性(Cohen's Kappa)从0.65提升至0.89。
影像报告:自动生成带关键病灶标记的放射学描述,三甲医院实测节省医生70%时间。
4.3 遥感监测
灾害评估:对洪涝区域进行多时相对比分析,灾害范围测算误差<5%。
农业普查:识别玉米植株密度与病虫害,准确率比传统方法高22%。
五、官方资源
项目主页:https://tiger-ai-lab.github.io/Pixel-Reasoner/
GitHub仓库:https://github.com/TIGER-AI-Lab/Pixel-Reasoner
论文PDF:https://arxiv.org/abs/2505.15966
在线Demo:https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
六、总结
Pixel Reasoner通过像素空间操作与内在动机学习的融合,实现了视觉推理领域的三大突破:细粒度理解(亚像素级分析)、主动认知(人类式探索)和可解释输出(视觉证据链)。其开源生态更推动技术民主化,让中小团队也能获得顶尖视觉分析能力。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4401.html


























