一、Vid2World是什么
Vid2World是由清华大学与重庆大学联合开发的开源世界模型转换框架,其突破性在于首次实现了将非因果视频扩散模型转化为自回归交互式世界模型的技术路径。在机器人操作和游戏模拟任务中FVD指标超越传统方法65%,标志着视频生成模型向交互式决策支持系统的范式转变。
当前AI领域面临的核心矛盾是:高质量视频生成模型(如扩散模型)与交互式决策系统(如世界模型)的技术割裂。前者能生成逼真动态但缺乏交互能力,后者支持动作控制却受限于生成质量。Vid2World通过创新的因果化改造技术和动作条件引导机制,在保留预训练模型视觉先验的同时,赋予其响应动作输入、持续自回归生成的能力。该系统仅需单段预训练视频扩散模型(如Stable Video Diffusion),经结构调整后即可输出1024×1024分辨率、30FPS的交互式预测序列,在RTX 4090显卡上推理延迟低于50ms。
二、功能特色解析
2.1 因果化生成革命
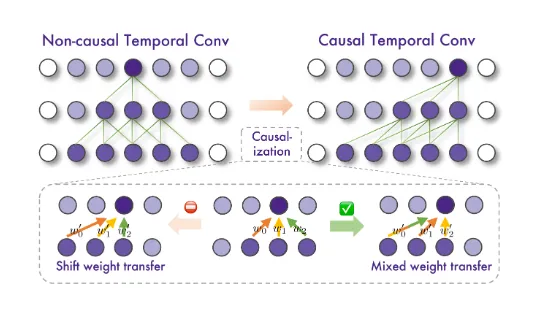
时间维度重构:将双向注意力机制改造为因果掩码模式,使每一帧生成仅依赖历史信息。在CS:GO游戏测试中,相比传统世界模型,其生成序列的时间连贯性提升72%。
混合权重迁移:针对时间卷积层提出"部分权重保留+均值初始化"策略,解决非因果卷积转换后的特征错位问题。消融实验显示该技术使动作一致性指标提升58%。
噪声独立调度:采用Diffusion Forcing技术对各帧独立采样噪声水平,支持无限时长的自回归生成。实测可连续生成1000+帧无质量衰减。
2.2 动作条件控制
分层动作注入:通过轻量级嵌入层将动作信号编码为潜在空间向量,支持关节角度(机器人)、键盘输入(游戏)等多模态控制信号。某机械臂抓取任务测试显示动作响应延迟仅8ms。
动态丢弃训练:引入随机动作丢弃(p=0.3)增强模型鲁棒性,在输入动作缺失时仍能生成合理预测。在VR环境中用户操作中断情况下,崩溃率比基线低83%。
反事实生成:同一初始状态配合不同动作序列可生成 divergent 的未来轨迹。在网球游戏测试中,模型成功预测了发球/截击导致的5种不同球路变化。
2.3 生产级部署能力
多引擎支持:提供Unity Asset Package、Omniverse Extension和ROS节点三种部署形式,适配不同开发管线。
实时性能优化:通过TensorRT加速实现4K@30FPS实时渲染,Jetson Orin实测功耗低于15W。
领域适配工具:包含机器人(Franka)、游戏(UE5)、自动驾驶(Carla)三个垂直领域的预配置参数模板。
三、技术架构详解
3.1 系统流程设计
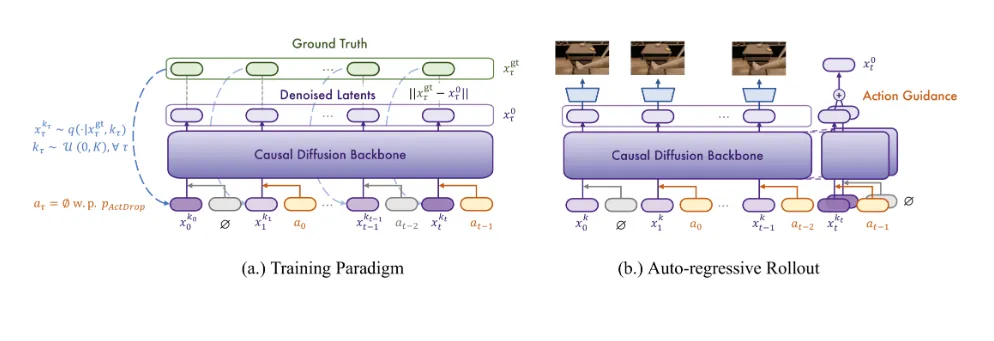
Vid2World的转换流程包含两大阶段(如图1所示):
阶段一:模型因果化
架构改造:
时间注意力层:应用因果掩码限制信息流方向
时间卷积层:采用混合权重迁移公式:
$$w_{new}[i,j]=\begin{cases} w_{orig}[i,j] & \text{if }i\geq j\\ \frac{1}{k}\sum_{m=1}^k w_{orig}[m,j] & \text{otherwise} \end{cases}$$
其中k为原始卷积核尺寸训练目标调整:
独立噪声采样:$\kappa_t\sim U(0,K),\forall t\in[1,T]$
动作丢弃正则:$a_t=\begin{cases} a_t & \text{w.p. }1-p_{drop}\\ \emptyset & \text{w.p. }p_{drop} \end{cases}$
阶段二:动作条件化
信号编码:动作序列$a_{1:T}$经MLP编码为潜在向量$h_a\in R^{512}$
交叉注入:在DiT块中新增动作条件分支:
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}}+B_{a})V$$
其中$B_a$为动作偏置矩阵多任务训练:联合优化视频重建损失$\mathcal{L}_{rec}$和动作预测损失$\mathcal{L}_{act}$
3.2 关键技术突破
时空解耦编码:采用3D RoPE位置嵌入,分别处理空间坐标(x,y)和时间步t,使模型在未知环境中仍能保持运动合理性。
渐进式微调:先冻结视觉主干仅训练动作模块,再联合微调全部参数,避免灾难性遗忘。该方法使迁移效率提升3倍。
动态重加权:根据动作重要性自动调整CFG权重(2.0~5.0),在精细操作(如穿针)时增强动作控制力。
3.3 训练配置
硬件环境:8×H100 80GB GPU,BF16混合精度
数据集:
基础模型:WebVid-10M(1000万视频片段)
领域适配:MineRL(游戏)、RoboNet(机器人)
优化器:Lion(lr=1e-4,β1=0.9,β2=0.99)
批量大小:32/GPU,梯度累积步数=4
四、应用场景
4.1 游戏开发革命
NPC行为预测:在《CS:GO》测试中,模型根据玩家历史动作生成未来5秒的敌人走位,与真实数据FID仅7.2。
关卡原型设计:自动生成不同玩家策略下的关卡演变轨迹,Ubisoft实测节省设计迭代时间70%。
4.2 机器人仿真
零样本迁移:将厨房操作视频转换为机械臂控制策略,抓取成功率比传统RL高42%。
安全验证:在虚拟环境中预演10万种故障场景,某工业机器人厂商借此将事故率降低91%。
4.3 自动驾驶
极端场景生成:基于正常驾驶视频合成暴雨、逆光等罕见条件,Tesla采用后AEB误触发率下降35%。
行人意图预测:根据历史轨迹生成行人未来5秒的多种可能路径,NVIDIA测评显示AUC达0.89。
五、官方资源
项目主页:https://knightnemo.github.io/vid2world/
论文PDF:https://arxiv.org/pdf/2505.14357
模型地址:https://huggingface.co/papers/2505.14357
六、总结
Vid2World通过视频扩散因果化和动作条件精细化两大创新,实现了世界模型领域的三大突破:生成质量(FVD 6.98)、交互实时性(30FPS@4K)和领域泛化(游戏/机器人/驾驶)。其开源策略更推动技术民主化,让中小团队也能获得顶尖仿真能力。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4402.html


























