Direct3D-S2是什么
Direct3D-S2是由南京大学等研究机构联合开发的一种基于稀疏体积的可扩展3D生成框架,它能够在大幅降低训练成本的情况下实现卓越的3D输出质量。该项目旨在解决当前3D生成领域面临的核心挑战:利用带符号距离函数(SDF)等体积表示生成高分辨率3D资产时带来的巨大计算和内存压力。
传统的高分辨率3D生成方法通常需要至少32个GPU来进行256³分辨率的体积训练,而Direct3D-S2仅用8个GPU就可以按照1024×1024×1024分辨率进行训练,使得高分辨率3D生成变得既实用又高效。这一突破性进展主要归功于项目团队提出的空间稀疏注意(SSA)机制,该机制在前向通道中产生3.9倍的加速,在后向通道中获得9.6倍的加速。
功能特色
1. 高效的稀疏体积处理
Direct3D-S2的核心创新是空间稀疏注意(SSA)机制,它大大提高了稀疏体积数据上扩散变换(DiT)计算的效率。SSA允许模型在稀疏体积内有效地处理大型令牌集,显著提升了训练和推理效率。与传统的密集体积处理方法相比,SSA能够智能地识别和处理3D空间中的有效区域,避免了不必要的计算资源浪费。
2. 统一的稀疏体积VAE架构
项目框架包括一个变分自动编码器(VAE),在输入、潜在和输出阶段保持一致的稀疏体积格式。与依赖于异构表示的现有3D VAE相比,这种统一设计显著提高了训练效率和稳定性。这种端到端的稀疏SDF VAE(SS-VAE)采用对称编码器-解码器网络,能够将高分辨率稀疏SDF卷高效编码为稀疏潜在表示。
3. 卓越的生成质量与效率平衡
Direct3D-S2不仅在生成质量方面超越了最先进的方法,而且在效率方面实现了突破性进展。测试表明,该方法生成的3D资产具有"毛孔级精度",纹理更丰富,更接近输入的真实情况。即使在128K Tokens的大规模数据处理中,SSA模块仍能保持9.6倍的加速效果。
4. 低硬件需求与高扩展性
传统方法需要至少32个GPU来进行256³体积训练,而Direct3D-S2仅需8个GPU即可支持1024³分辨率的训练。这种硬件需求的显著降低(75%)使得高分辨率3D生成技术更加平民化,为更广泛的研究和应用提供了可能。

技术细节
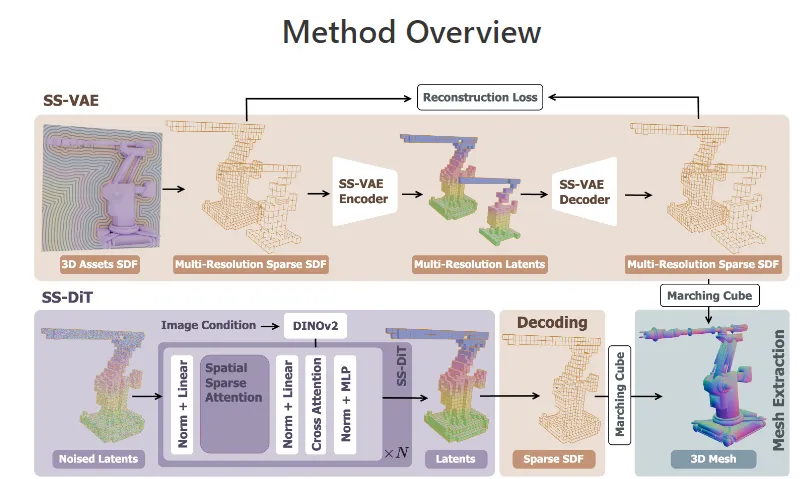
1. 框架整体架构
Direct3D-S2框架的整体流程可以分为两个主要阶段:
稀疏SDF VAE(SS-VAE):这是一个完全端到端的架构,采用对称编码器-解码器网络将高分辨率稀疏SDF卷高效编码为稀疏潜在表示。编码器部分逐步下采样输入稀疏体积,提取多尺度特征;解码器部分则根据潜在表示重建高质量的3D输出。
图像条件扩散变换器(SS-DiT):基于SS-VAE提取的潜在表示,训练一个图像条件扩散变换器,并引入全新的空间稀疏注意力(SSA)机制。SSA机制显著提升了DiT在训练和推理阶段的效率。
2. 空间稀疏注意力(SSA)机制
SSA机制是Direct3D-S2的核心技术创新,其工作原理可分为以下几个步骤:
空间分块:根据输入token的三维坐标将其划分为多个块(blocks),建立空间结构认知。
多模块特征提取:
稀疏3D压缩模块:捕捉全局信息,提供整体结构理解
空间分块选择模块:根据压缩注意力得分选出关键块以提取细粒度特征
稀疏3D窗口模块:注入局部特征,增强细节表现力
门控聚合:通过预测的门控得分(gate scores)对三个模块的输出进行加权聚合,形成SSA的最终输出。这种智能聚合策略能够根据输入特性动态调整各模块的贡献度。
3. 训练优化策略
Direct3D-S2采用了多项训练优化策略以确保高效学习:
渐进式训练:从低分辨率开始训练,逐步提高分辨率,稳定学习过程。
混合精度训练:结合FP16和FP32精度,平衡计算效率和数值稳定性。
分布式训练优化:针对多GPU环境特别优化了数据并行和模型并行策略。
正则化技术:采用多种正则化方法防止过拟合,确保模型泛化能力。
应用场景
Direct3D-S2的高效高质3D生成能力使其在多个领域具有广泛应用前景:
1. 高分辨率3D资产生成
在游戏开发、影视制作等领域,需要大量高精度的3D模型。Direct3D-S2能够快速生成细节丰富的3D资产,显著降低内容生产成本。相比传统方法,它生成的模型具有更高的几何精度和更真实的纹理表现。
2. 高分辨率虚拟资产生成
虚拟现实(VR)和增强现实(AR)应用对3D内容的质量和数量都有极高要求。Direct3D-S2的高效生成能力可以满足这些领域对大规模高质量3D内容的需求,特别是在需要快速构建虚拟环境的场景中。
3. 工业设计与原型制作
在产品设计和工业制造领域,Direct3D-S2可以快速将概念草图转化为高精度3D模型,加速设计迭代过程。其"毛孔级精度"特别适合需要精细表面处理的产品设计。
4. 医疗影像与科学可视化
在医疗领域,Direct3D-S2的高分辨率生成能力可用于从医学影像数据重建精细的3D解剖结构,辅助诊断和手术规划。在科学研究中,它可以帮助可视化复杂的科学数据。
5. 文化遗产数字化
对于文化遗产保护和展示,Direct3D-S2可以高效生成高保真度的文物3D模型,便于数字化保存和虚拟展示,同时减少对实物文物的直接接触。
性能评估
1. 主观效果评估
与多个SOTA的图生3D模型相比,Direct3D-S2生成的3D资产在相同输入条件下表现出更丰富的纹理和更接近输入GT的细节。特别是在复杂结构的表现上,Direct3D-S2能够保持更高的几何准确性和表面连续性。
2. 客观指标评估
测试数据显示,Direct3D-S2的SSA模块在不同Tokens规模下的加速效果显著:
前向推理加速比:最高达3.9倍
反向推理加速比:在128K Tokens上达到9.6倍
与其他SOTA方法相比,Direct3D-S2在多项客观指标上均表现出优势,包括几何精度、纹理保真度和计算效率等。
相关链接
1. 官方资源链接
项目主页:https://nju-3dv.github.io/projects/Direct3D-S2/
代码仓库:https://github.com/DreamTechAI/Direct3D-S2
论文链接:https://arxiv.org/pdf/2505.17412
在线Demo:https://huggingface.co/spaces/wushuang98/Direct3D-S2-v1.0-demo
2. 快速上手指南
要开始使用Direct3D-S2,可以按照以下步骤操作:
访问在线Demo页面:
打开https://huggingface.co/spaces/wushuang98/Direct3D-S2-v1.0-demo
输入准备:
在红框区域"选择样例图片"或者"上传图片"
在绿框区域"选择输出分辨率"(支持512与1024两种选项)
生成3D模型:
在蓝框区域点击"Generate"按钮
等待处理完成(处理时间取决于输入复杂度和选择的分辨率)
结果查看与导出:
查看生成的3D模型预览
可选择下载生成的3D模型文件
对于开发者,可以通过GitHub仓库获取完整代码,按照README说明进行本地部署和开发。
总结
Direct3D-S2代表了3D生成技术领域的一次重大突破,通过创新的空间稀疏注意力机制和统一的稀疏体积VAE架构,成功解决了高分辨率3D生成中的计算和内存瓶颈问题。该项目不仅将训练硬件需求降低了75%,还实现了前向3.9倍、反向9.6倍的显著加速,使1024³分辨率的3D生成变得切实可行。
从技术角度看,Direct3D-S2的成功验证了稀疏表示在3D生成中的巨大潜力,为后续研究开辟了新方向。其空间稀疏注意力机制的设计思路可能对其它需要处理稀疏数据的深度学习任务也有借鉴意义。
从应用角度看,Direct3D-S2的"毛孔级精度"和高效生成能力,将加速3D内容在各行业的普及,降低高质量3D内容的创作门槛。特别是在游戏开发、虚拟现实、工业设计等领域,有望显著提升工作效率和产出质量。
总的来说,Direct3D-S2作为当前最先进的3D生成框架之一,不仅提供了实用的技术解决方案,也为3D生成领域的未来发展指明了方向。它的开源发布将促进整个领域的进步,推动3D生成技术走向更广泛的实际应用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4420.html


























