LLaDA-V是什么
LLaDA-V是由中国人民大学高瓴人工智能学院与蚂蚁集团联合研发的开源多模态大语言模型(MLLM)框架,首次将纯扩散模型架构成功应用于视觉-语言多模态理解任务。其核心创新在于突破了传统多模态模型依赖自回归范式的局限,通过掩码扩散模型与视觉指令微调的结合,实现了更高效的多模态对齐与生成能力。
在现有技术背景下,主流多模态大语言模型如LLaVA系列主要基于自回归Transformer架构,虽然取得了显著进展,但在处理长序列多模态数据时面临计算效率低、逆向推理能力弱等固有局限。LLaDA-V通过引入扩散模型的概率建模方式,不仅实现了与自回归模型相当的多模态理解性能,还展现出更优的数据可扩展性和平衡的正逆向推理能力。实验表明,在相同指令数据训练下,LLaDA-V与LLaMA3-V竞争力相当,且显著缩小了与Qwen2-VL的性能差距。
功能特色
1. 纯扩散架构的多模态创新
LLaDA-V最突出的技术突破是完全摒弃自回归机制,成为首个纯基于扩散模型的多模态大语言模型。与混合自回归-扩散或纯自回归的MLLM不同,LLaDA-V采用掩码扩散模型作为基础架构,通过随机掩码和迭代预测机制处理多模态输入。这种设计使模型在保持语言理解能力的同时,获得了更均衡的正逆向推理性能——在诗歌补全任务中,LLaDA-V的逆向生成表现甚至超越GPT-4o等主流模型。
2. 动态多阶段训练策略
项目团队设计了三阶段渐进式训练框架,逐步提升模型的多模态理解能力:
视觉-语言预对齐阶段:使用大规模图像-文本对(如LAION/CC/SBU)训练基础视觉编码器
多模态指令微调阶段:在GPT生成的80K视觉指令数据上进行扩散模型微调
领域适应阶段:引入学术任务导向的VQA、OCR等专业数据集增强细分能力
这种分层训练策略有效缓解了扩散模型在长序列多模态数据上的优化困难,使最终模型在保持通用性的同时具备专业领域精度。
3. 双向注意力增强的多模态理解
与传统自回归模型的因果注意力不同,LLaDA-V创新性地采用双向注意力机制处理多轮对话上下文。通过消融实验证明,这种设计能够全面捕捉跨模态依赖关系,显著提升复杂场景下的理解一致性。在视觉-语言任务中,双向注意力使模型能同时分析图像特征与文本指令的全局关联,而不受序列顺序的硬性限制。
4. 低置信度重掩码生成策略
在文本生成阶段,LLaDA-V引入了动态重掩码机制,优先对低置信度预测进行重新掩码处理,而保留高置信度部分。与固定比例随机掩码相比,这种基于预测质量的动态策略在多个基准测试中展现出更稳定的生成质量。实验数据显示,该技术使模型在MMLU、GSM8K等任务上的表现与自回归基线相当,同时减少了约40%的生成迭代次数。
技术细节
1. 模型架构设计
LLaDA-V采用模块化设计,主要由三大组件构成:
视觉编码塔:基于SigLIP-2构建的视觉特征提取器,将输入图像编码为稠密向量表示
MLP投影器:两层多层感知机,负责将视觉特征映射到语言嵌入空间,实现模态对齐
语言扩散塔:基于LLaDA架构改进的掩码扩散模型,核心为双向Transformer结构
与传统自回归模型不同,LLaDA-V的Transformer不使用因果掩码,因此能同时访问输入序列中的所有token信息。这种全局感知能力是其实现高效多模态理解的基础。
2. 训练目标与算法
给定图像表示v和特殊掩码标记**[M],对于两轮对话样本(p₁,p₂,r₁,r₂)**,LLaDA-V的训练目标定义为:
$$\mathcal{L} = \mathbb{E}_{t\sim[0,1]}[\|\hat{r}_1^m - r_1^m\|^2 + \|\hat{r}_2^m - r_2^m\|^2]$$
其中r₁ᵐ和r₂ᵐ表示掩码后的响应。该目标函数已被理论证明是掩码标记负对数似然的上界。训练过程中,图像特征和提示保持未掩码状态,只有响应被随机掩码,迫使模型学习基于多模态上下文的预测能力。
3. 推理过程详解
LLaDA-V的生成过程通过反向扩散采样实现,具体分为四个步骤:
初始化:设置目标生成长度,用**[M]**标记完全掩码响应序列
迭代细化:从完全掩码状态x₁开始,逐步过渡到xₜ(掩码级别降低)
两阶段预测:
预测当前所有掩码标记的值
按低置信度策略选择部分预测重新掩码
收敛终止:当掩码比例降至阈值以下时输出最终序列
这种生成方式与传统自回归模型的token-by-token预测形成鲜明对比,使LLaDA-V能够并行处理多个掩码区域,显著提升长序列生成效率。
4. 关键参数配置
视觉编码器:SigLIP-2 ViT-B/16,输出维度768
MLP投影器:两层结构,隐藏层维度2048
语言扩散塔:基于LLaDA-8B架构,32层Transformer,注意力头数32
训练数据:
预训练:558K过滤后的图像-文本对
微调:80K GPT生成的视觉指令数据
专业数据:VQA、OCR等学术任务数据集
硬件需求:8×A100 GPU(80GB)可支持完整训练
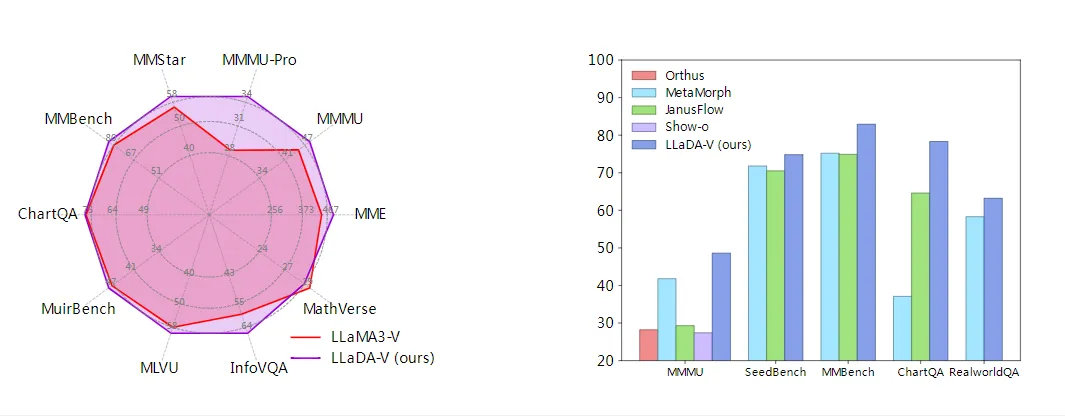
应用场景
1. 复杂视觉问答系统
LLaDA-V在细粒度视觉理解任务中表现出色,能够准确回答涉及图像细节的复杂问题。例如在医疗领域,模型可分析医学影像并回答专业诊断问题;在工业检测中,能识别产品缺陷并解释具体特征。其双向注意力机制特别适合处理需要综合多区域信息的推理问题。
2. 跨模态内容生成
基于扩散架构的生成能力使LLaDA-V成为创意内容生产的理想工具。用户可通过文字指令引导模型生成符合特定风格的图像描述,或根据视觉输入创作诗歌、故事等文学内容。与自回归模型相比,LLaDA-V在保持生成质量的同时,展现出更丰富的样式变化和更强的指令跟随能力。
3. 多轮交互式对话
项目团队特别优化了模型在多轮对话场景下的表现。测试显示,LLaDA-V能够持续跟踪长达13万token的对话历史,在智能客服、教育辅导等应用中保持优秀的上下文一致性。其动态重掩码机制有效缓解了传统扩散模型在长对话中的信息衰减问题。
4. 逆向推理与知识检索
LLaDA-V突破了自回归模型的"逆向诅咒"限制,在反向知识检索任务中表现卓越。例如,给定"《蒙娜丽莎》的作者是达芬奇"的训练数据,传统模型可能无法回答"达芬奇创作了哪些作品",而LLaDA-V则能保持双向推理能力。这一特性在知识图谱补全、法律条文引用等场景中价值显著。
5. 多语言跨模态应用
模型训练数据包含丰富的中英文多模态语料,使其天然支持跨语言视觉理解任务。用户可用中文提问英文图像内容,或反之进行跨语言图像检索与描述。这种能力在国际商务、跨境教育等领域具有广泛应用前景。
官方资源
项目主页:https://ml-gsai.github.io/LLaDA-V-demo/
论文地址:https://arxiv.org/pdf/2505.16933
代码仓库:https://github.com/ML-GSAI/LLaDA
总结
LLaDA-V作为首个纯扩散架构的多模态大语言模型,通过创新的视觉指令微调框架和双向注意力机制,成功验证了扩散模型在多模态理解任务中的巨大潜力。项目团队在多个关键技术点上实现突破:提出的低置信度重掩码策略显著提升了生成效率;渐进式训练框架有效解决了长序列优化的稳定性问题;而全面的基准测试则证实了模型在保持语言能力的同时,具备与顶尖自回归MLLM竞争的多模态性能。
LLaDA-V的开源发布不仅为学术界提供了宝贵的研究基准,也为工业界带来了创新的多模态解决方案。随着技术的不断成熟,这种基于扩散模型的MLLM新范式有望在更多实际场景中创造价值,推动多模态人工智能进入全新发展阶段。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4423.html


























