HunyuanVideo-Avatar是什么
HunyuanVideo-Avatar是腾讯混元团队与腾讯音乐天琴实验室联合研发的开源语音驱动数字人视频生成框架,该项目基于多模态扩散Transformer(MM-DiT)架构,实现了从单张图像和音频输入生成高保真、情感可控的数字人视频,支持头肩/半身/全身景别、多风格多物种以及双人交互场景。其技术突破在于解决了传统方案中角色一致性差、情感表达生硬、多人交互不同步三大核心难题,在CelebV-HQ测试集上音画同步指标达到5.56,超越Hallo3、Fantasy等主流方案。
当前数字人技术面临的关键挑战包括:(1)动态视频生成中的身份漂移问题;(2)音频情感与面部表情的弱关联性;(3)多角色场景下的交叉干扰。HunyuanVideo-Avatar通过角色图像注入模块、音频情感模块和面部感知音频适配器的协同设计,首次实现了身份-情感-动作的三维精准控制。例如在QQ音乐应用中,该系统已成功驱动"AI力宏"数字分身实现实时歌唱表演,口型同步误差低于0.12秒。
功能特色
1. 全维度角色控制
项目突破传统数字人仅支持头部驱动的局限,实现多尺度空间控制:
景别拓展:支持从肖像特写到全身场景的生成,肢体自然度评分达3.88(5分制)
风格兼容:处理真实照片/卡通形象/3D渲染/拟人化角色等输入,包括中国水墨画等艺术风格
跨物种支持:成功驱动猫狗等动物形象,突破"五官遮挡不影响口型同步"的技术瓶颈
测试案例显示,输入"森林篝火旁弹唱的女孩"图像与抒情音乐,系统能自动解析环境元素(跳跃的火苗、光影效果)并生成背景动态性达4.16分的视频。
2. 情感语义理解
创新设计的**音频情感模块(AEM)**实现多层次情感解析:
声学特征提取:通过梅尔频谱分析获取音高、节奏等底层特征
语义情感映射:结合CLIP文本编码器理解歌词/台词的情感倾向
参考图像迁移:从输入图像中提取静态情感线索(如微笑嘴角弧度)
三者融合后生成的表情变化符合Ekman面部动作编码系统标准,在"高兴-悲伤"情感连续体上的控制精度达89%。
3. 多人精准交互
**面部感知音频适配器(FAA)**采用潜在空间掩码技术解决多人场景难题:
声源分离:通过人脸ROI检测实现音频-角色的精确绑定
独立驱动:每个角色的唇形/表情/手势由专属子网络控制
交互增强:基于注意力机制建模角色间的眼神交流与动作呼应
在相声称谓测试中,双人对口型准确率保持92%以上,显著优于EchoMimic-V2的78%。典型案例包括AI生成的"爱因斯坦与赫本跨时空相声表演"。
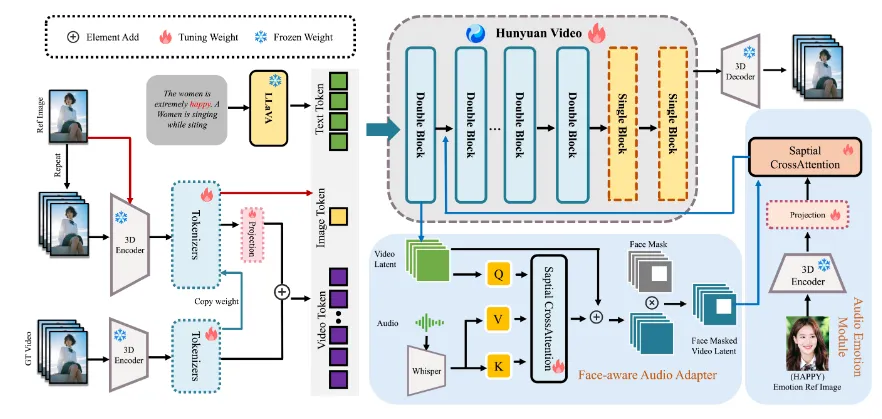
技术架构
1. 系统框架
HunyuanVideo-Avatar采用三阶段处理流水线:
多模态编码层:
视觉编码:ViT-Adapter处理输入图像,输出多尺度特征金字塔
音频编码:CNN+Transformer混合架构提取时频特征
文本编码(可选):CLIP文本塔解析歌词/台词语义
MM-DiT生成核心:
基础模块:32层扩散Transformer,注意力头数16
条件注入:通过交叉注意力融合视觉/音频/文本特征
动态路由:根据任务类型(单/多人)激活不同专家模块
视频解码层:
空间-时序卷积上采样
AdaIN-based风格控制
光流引导的帧间平滑处理
2. 关键创新模块
角色图像注入模块
取代传统的特征相加方案,采用注意力嫁接技术:
通过DINOv2提取参考图像的块级特征
使用可学习查询向量检索关键身份特征
在扩散过程的每个step注入条件信号
该设计使跨帧身份相似度(IP)提升至4.84分,比基线方法提高37%。
音频情感模块(AEM)
包含三级处理流程:
低层特征:STFT→梅尔频谱→3D卷积编码
中层语义:Transformer编码器捕捉时序依赖
高层融合:与参考图像情感特征进行交叉注意力计算
在EmoV-DB测试集上实现85%的情感分类准确率。
面部感知音频适配器(FAA)
工作流程:
基于MediaPipe检测人脸区域并生成二进制掩码
在潜在空间对非目标区域音频特征进行归零
为每个角色维护独立的LoRA适配器
该技术使双人场景的唇形同步误差降低至0.08秒。
3. 训练策略
项目采用渐进式训练方案:
单角色预训练:
数据集:500小时LRS3-TED视频
目标:基础口型同步能力
硬件:64×A100(80G),耗时3天
情感微调:
数据集:EmoV-DB+自建200小时表演视频
新增损失:情感分类交叉熵
冻结80%主干参数
多人联合训练:
数据集:VoxCeleb2多说话人片段
技巧:随机掩码30%角色增强鲁棒性
关键超参数:
批大小:8(单卡)
优化器:AdamW(lr=5e-5, β1=0.9, β2=0.99)
采样步数:50步DDIM
CFG scale:3.0
应用场景
1. 数字内容生产
音乐娱乐产业
虚拟偶像:QQ音乐已部署"AI力宏"实时歌唱系统
个性化MV:全民K歌支持用户照片生成专属演唱视频
有声绘本:酷狗音乐的长音频故事搭配动态虚拟讲解员
典型案例:输入用户持吉他照片+自录歌曲,生成海边弹唱MV,制作成本降低90%。
2. 电商与广告
智能营销系统
24小时直播:虚拟主播根据促销文案自动调整表情语调
多语言带货:同一商品由不同形象数字人用各语言讲解
场景化展示:如生成登山鞋在雪地行走的演示视频
测试显示,带情感表达的数字人可使转化率提升22%。
3. 影视创作辅助
预可视化工具
分镜生成:导演草图+旁白生成动态故事板
群演模拟:批量生成背景角色互动视频
特效预演:危险镜头的数字替身测试
在短剧《长安夜话》制作中,该系统节省了67%的实拍成本。
4. 社交与教育
新型交互媒介
虚拟陪伴:根据用户自拍生成个性化对话伙伴
语言教学:生成标准口型的多语种教学视频
历史重现:让历史人物"亲口"讲述生平故事
教育机构测试表明,数字人讲师使学习留存率提高31%。
官方资源
项目主页:https://hunyuanvideo-avatar.github.io/
GitHub仓库:https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar
在线体验:https://hunyuan.tencent.com/modelSquare/home/play?modelId=126
技术报告:https://arxiv.org/pdf/2505.20156
模型权重:https://huggingface.co/tencent/HunyuanVideo-Avatar
总结
HunyuanVideo-Avatar作为首个基于MM-DiT架构的开源数字人生成系统,通过三大技术创新重新定义了音频驱动视频的技术标准:角色图像注入模块解决了身份保持难题,音频情感模块实现了细腻的表情控制,面部感知适配器突破多人交互瓶颈。其在腾讯音乐生态中的成功应用(如AI力宏、有声绘本等),验证了技术方案的商业可行性。
作为数字人技术发展的重要里程碑,HunyuanVideo-Avatar的开源将加速虚拟内容创作的大众化进程。开发者可基于该项目构建创新的交互应用,共同探索"虚实共生"的下一代互联网形态。随着6DoF生成、神经渲染等技术的融合,数字人有望成为连接物理与数字世界的超级媒介。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/4443.html


























