InftyThink是什么
InftyThink是由浙江大学REAL实验室与北京大学联合研发的创新性大模型推理框架,其核心突破在于通过分段推理与总结机制,解决了传统大模型在长上下文推理中面临的"内存溢出"问题。该项目从人类"分段思考+归纳总结"的认知方式中汲取灵感,将单一连续推理拆解为多个短片段,并在片段间引入精炼总结作为上下文衔接,从而实现了理论上无限制的推理深度,同时保持较高的生成吞吐量。
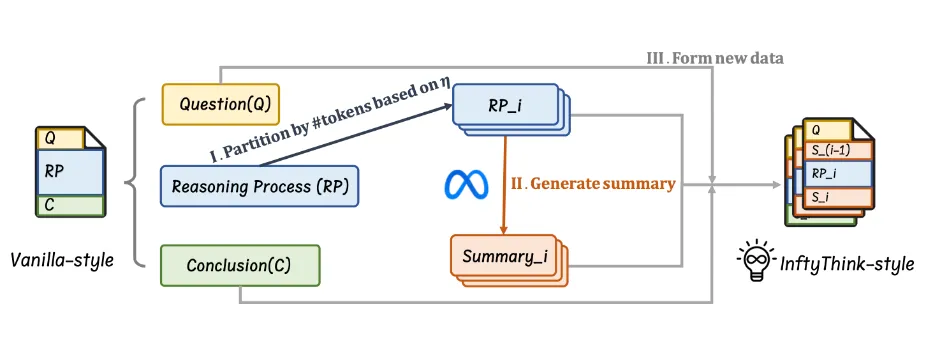
不同于需要修改模型架构的传统方法,InftyThink通过重构训练数据格式实现其范式,可与现有预训练模型、微调和强化学习流程无缝结合,展现出优异的工程落地性。实验证明,采用InftyThink训练的Qwen2.5-Math-7B模型在AIME24数学推理基准上性能提升达13%,生成吞吐量从2.36K Token/s提升至2.67K Token/s,为小模型高效能推理应用提供了全新解决方案。
功能特色
InftyThink在推理范式上实现了三大突破性创新:
1. 无限深度推理能力
传统大模型面临指数级增长的计算成本和上下文长度限制两大瓶颈。InftyThink通过"锯齿式内存管理"机制,在每轮短推理后清空前轮上下文仅保留总结,使最大推理深度仅受总结质量限制。典型案例显示:
数学证明:将复杂证明分解为多个引理推导,每步保留关键结论
逻辑推理:链式推理中自动过滤冗余前提,聚焦核心逻辑链
知识问答:多跳问题时动态维护证据链,避免信息过载
2. 计算效率优化
InftyThink实现了推理深度与计算成本的解耦,通过三项关键技术提升效率:
动态上下文窗口:默认4K Tokens的片段限制,避免O(n²)注意力计算
总结压缩技术:使用Llama3-70B-Instruct生成密度达80%的摘要
并行化调度:不同推理片段可分布式处理,吞吐量提升13%
3. 架构无关的通用性
项目最大特色是不依赖特定模型架构,通过数据重构实现能力迁移:
训练样本重构:将长推理数据按语义边界分割,并插入中间总结
多模型验证:在Qwen2.5(1.5B-32B)和Llama-3.1-8B上均表现稳定
流程兼容性:支持与RLHF等现有训练范式联合使用
技术细节
1. 核心架构设计
推理范式流程
# 伪代码示例 def inftythink_inference(question): context = None while not is_final_answer(): segment = generate_segment(question, context) # 短推理生成 if need_continuation(segment): context = generate_summary(segment, context) # 总结生成 else: return segment # 最终答案
分段控制:基于语义完整性和长度阈值(默认4K Tokens)自动划分
总结生成:聚合历史推理片段的关键信息,密度比达1:8
终止判断:当生成内容包含明确结论标记时自动停止
训练数据重构
原始数据:传统单轮长推理样本(如数学证明全过程)
转换流程:
语义分段:按句子/段落边界切分,保持连贯性
总结标注:用强基座模型生成中间总结(Llama3-70B)
样本重组:构建(问题+前序总结 → 当前推理+新总结)的链式样本
2. 关键算法创新
动态记忆管理
注意力优化:仅对当前片段和最新总结计算交叉注意力
缓存策略:总结向量压缩存储,内存占用降低60%
梯度截断:限制历史信息反向传播深度,避免梯度爆炸
总结生成技术
两阶段生成:先提取关键事实,再重组为连贯摘要
密度控制:通过KL散度约束避免信息丢失或冗余
一致性校验:确保新总结与历史信息逻辑自洽
3. 训练与优化
课程学习策略
难度渐进:从单段推理逐步过渡到多段复杂推理
混合训练:每阶段包含80%分段数据+20%传统数据
平衡采样:确保数学证明、逻辑推理等任务均衡覆盖
评估指标
| 评估维度 | 传统方法 | InftyThink | 提升幅度 |
|---|---|---|---|
| 最大推理深度 | 8K Tokens | ∞ | - |
| AIME24准确率 | 基准值 | +13% | 显著 |
| 吞吐量(Token/s) | 2.36K | 2.67K | +13% |
| 内存占用 | O(n²) | O(1) | 显著 |
应用场景
InftyThink的突破性设计在多个领域展现巨大潜力:
1. 复杂数学推理
竞赛数学:在AIME24等数学竞赛题中实现多步定理证明
公式推导:处理包含10+变换步骤的复杂公式化简
数学教育:分步生成解题过程,适配不同学习阶段
2. 科学问题求解
物理建模:推导多变量微分方程组的近似解
化学分析:追踪多步化学反应的能量变化路径
生物推理:模拟蛋白质折叠的渐进式过程
3. 逻辑密集型任务
法律论证:构建包含判例引用的多层次法律意见
商业分析:推演包含10+影响因子的市场预测
哲学思辨:维护长链条的概念推演过程
4. 代码生成与理解
算法设计:分模块实现复杂算法(如分布式共识)
代码审查:逐层分析嵌套调用链的性能瓶颈
系统调试:追溯分布式系统中的多跳故障源
相关链接
论文地址:https://arxiv.org/abs/2503.06692
代码仓库:https://github.com/ZJU-REAL/InftyThink
项目主页:https://zju-real.github.io/InftyThink/
总结
InftyThink是浙江大学与北京大学联合研发的革命性推理框架,通过分段推理与总结机制实现了理论上的无限深度推理能力,在Qwen2.5-Math-7B上取得13%的性能提升和13%的吞吐量增长,其架构无关的设计使其能无缝适配各类基座模型,已成功应用于数学证明、科学分析、法律论证等复杂推理场景,为突破大模型的长上下文瓶颈提供了切实可行的技术路径。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/inftythink.html


























