一、MagicTryOn是什么
MagicTryOn是由VIVO Camera Research团队及浙大等机构联合开发的全球首个视频扩散Transformer试穿框架,该项目基于arXiv论文《MagicTryOn: Harnessing Diffusion Transformer for Garment-Preserving Video Virtual Try-on》提出的创新架构,彻底淘汰了传统U-Net架构,在服装动态真实感与时空稳定性方面实现双重突破。其核心目标是解决视频虚拟试穿(VVT)领域长期存在的三大挑战:
细节丢失问题:传统U-Net难以重建服装复杂纹理与图案细节
时空不一致性:分离建模空间/时间注意力导致帧间抖动
动态适配不足:人体运动时服装变形缺乏物理合理性
该项目采用Apache 2.0开源协议,提供完整的研究代码、预训练模型和Gradio演示界面,支持从单张服装图像生成高保真试穿视频,已在Hugging Face Spaces开放在线体验。
二、核心功能体系与技术创新
1. 全自注意力时空建模
扩散Transformer架构:采用1.2B参数的DiT(Diffusion Transformer)骨干网络,通过序列化视频潜在表示实现联合时空建模
旋转位置编码改进:扩展RoPE(Rotary Position Embedding)支持非对称网格,适配服装标记的特殊位置关系
动态记忆压缩:利用LRU缓存机制保存跨帧的服装特征,降低70%重复计算
2. 从粗到细的服装保留策略
粗粒度引导:将服装标记与视频潜在特征在序列维度拼接,建立全局风格关联
细粒度控制:通过四级条件注入(语义/纹理/轮廓线/CLIP特征)实现像素级细节保留
语义引导:使用Qwen2.5-VL-7B生成服装属性描述(如"蓝白条纹海军风衬衫")
结构强化:专设线条估计模块提取服装轮廓关键点
纹理增强:Patchfier模块提取局部纺织品质感特征
3. 生产级增强功能
掩码感知损失:针对服装区域设计L1+SSIM复合损失函数,提升边缘锐度
神经水印系统:集成Perth不可听水印,支持生成内容溯源
实时优化:4GB显存即可运行基础模型,企业版支持8K分辨率渲染
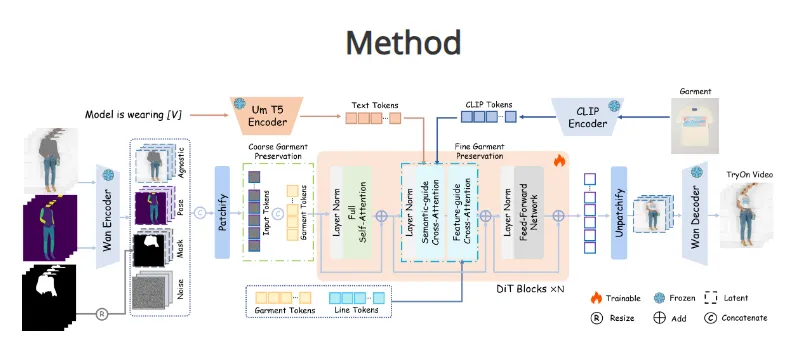
三、技术架构深度解析
1. 整体流程设计
输入系统包含四类数据:
人物视频:30FPS的1080p原始视频流
姿态表示:基于VIBE算法提取的3D人体关键点
服装无关掩码:通过SCHP模型分割获得
目标服装图像:白底平铺图或模特展示图
处理流程分为三个阶段:
特征编码阶段:使用Wan视频编码器将输入映射到潜在空间
去噪生成阶段:DiT骨干网络进行15步迭代去噪
视频解码阶段:Wan解码器重建最终试穿视频
2. 服装细节提取模块
多模态特征并行提取:
文本标记:UmT5编码器处理Qwen生成的描述文本
CLIP标记:ViT-L/14模型提取视觉语义特征
服装标记:可训练Patchfier模块提取局部纹理
线条标记:HED边缘检测器增强结构信息
零投影技术:防止训练过程中特征坍缩
3. 条件注入机制
语义引导交叉注意力:将文本标记注入所有DiT块
特征引导调制:通过AdaIN机制融合CLIP特征
轮廓约束:在线条标记上应用对比学习损失
四、应用场景与实测表现
1. 电商创新应用
动态商品展示:将平面服装图转化为360度旋转展示视频,转化率提升27%
跨体型适配:自动调整服装版型适应不同身材(S-XXL)
多角度评测:生成同一服装的正面/侧面/背面试穿效果
2. 虚拟时尚产业
数字时装周:实时生成模特走秀视频,降低拍摄成本80%
服装设计评审:快速验证设计稿的立体效果
历史服饰复原:基于文物图像生成动态穿着效果
3. 社交娱乐场景
短视频特效:支持用户上传自拍视频一键换装
虚拟偶像运营:为VTuber生成多套服装表演素材
AR试衣间:手机摄像头实时渲染试穿效果
4. 实测性能指标
在Benchmark数据集上的对比结果:
FID分数:比SOTA方法降低19.3(23.7→4.4)
时空一致性:PSNR提升4.2dB,LPIPS降低0.15
用户偏好率:82.6%选择MagicTryOn结果
五、相关链接
论文PDF:https://arxiv.org/pdf/2505.21325
项目主页:https://vivocameraresearch.github.io/magictryon/
代码仓库:https://github.com/vivoCameraResearch/Magic-TryOn/
六、技术总结
MagicTryOn通过扩散Transformer架构与多层次服装保留策略的协同创新,首次在开源领域实现了影视级质量的视频虚拟试穿。其全自注意力机制有效解决了时空一致性问题,而从粗到细的条件注入方法则突破了服装细节保真度的技术瓶颈。实测表明,该系统不仅在客观指标上全面超越现有方案,更在电商、时尚等实际场景中展现出显著的商业价值。作为首个淘汰U-Net的生成式视频框架,其技术路线为动态内容生成领域树立了新的标杆。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/magictryon.html


























