Playmate是什么
Playmate是由广州趣丸科技团队提出的一种基于3D隐式空间引导扩散模型的双阶段训练框架,旨在生成高质量且可控的肖像动画视频。该项目通过解耦面部属性(如表情、唇部动作和头部姿态),结合情绪控制模块,实现了对生成视频的精细控制。通俗来讲,Playmate的核心功能是给定一张静态照片和一段音频,即可生成对应的动态视频,同时还能精准控制人物的表情和头部姿态。
该项目的研究成果已被人工智能顶会ICML 2025收录,在视频质量、唇同步准确性和情绪控制灵活性方面均优于现有方法,是音频驱动肖像动画领域的重大进展。根据ICML 2025的数据显示,会议共收到12,107篇有效投稿,录用3,260篇,录用率为26.9%,而Playmate能从全球顶尖机构的激烈竞争中脱颖而出,充分证明了其技术创新性与学术价值。
Playmate完全由趣丸团队自主研发,相关技术已成功应用于"趣丸趣影"数字人产品,在电商带货、文娱及社交场景中展现出强大的实用价值。团队长期致力于数字人相关技术的研发,通过0样本/定制化/照片等模式,可实现数字人的快速制作,目前已成为美团、抖音等平台市场占有率最高的数字人技术提供商之一。
功能特色
Playmate在音频驱动肖像动画领域具有多项突破性功能特色,解决了当前技术面临的三大核心挑战:
1. 精准的唇同步能力
传统音频驱动方法难以精确匹配语音与唇部运动,导致生成的动画显得不自然。Playmate通过运动解耦模块和扩散Transformer技术,显著提升了唇同步精度。实验数据显示,在Sync-C(基于SyncNet的唇同步置信度分数)和Sync-D(唇同步特征距离)指标上,Playmate分别达到8.580和6.985,优于多数对比方法。
项目展示的案例中,Playmate能够实现精确的唱歌对口型效果,即使是复杂的音乐节奏和歌词变化,生成的唇部动作也能保持高度同步。这种能力对于虚拟歌手、数字主持人等应用场景尤为重要。
2. 灵活的表情与姿态控制
现有方法通常将表情和头部姿态与音频信号强耦合,难以独立调整。Playmate创新性地引入3D隐式空间解耦技术,将面部属性分离为表情、唇部运动和头部姿态三个独立维度。
用户可以通过情绪控制模块精细调节生成视频的情感状态。如图1(a)所示,Playmate能够根据同一音频片段生成愤怒(angry)、厌恶(disgusted)、轻蔑(contempt)、恐惧(fearful)、快乐(happy)、悲伤(sad)和惊讶(surprised)等多种情感状态的动态视频。这种解耦控制能力使Playmate在影视制作、游戏角色动画等领域具有独特优势。
3. 广泛的身份适应性
Playmate在多种风格的肖像上表现出色,包括真实人脸、动画和艺术肖像。项目展示的案例中,即使是达芬奇的名作《蒙娜丽莎》,Playmate也能让其从"神秘的微笑"变身N种情绪表情,展现了算法强大的泛化能力。
这种广泛适应性源于Playmate的双阶段训练框架:第一阶段专注于运动序列生成,第二阶段引入情绪控制,两者结合确保了算法对不同身份特征的保持能力。定量评估显示,Playmate在CSIM(余弦相似度)指标上达到0.848,表明其能很好地保持输入图像的身份特征。
技术细节
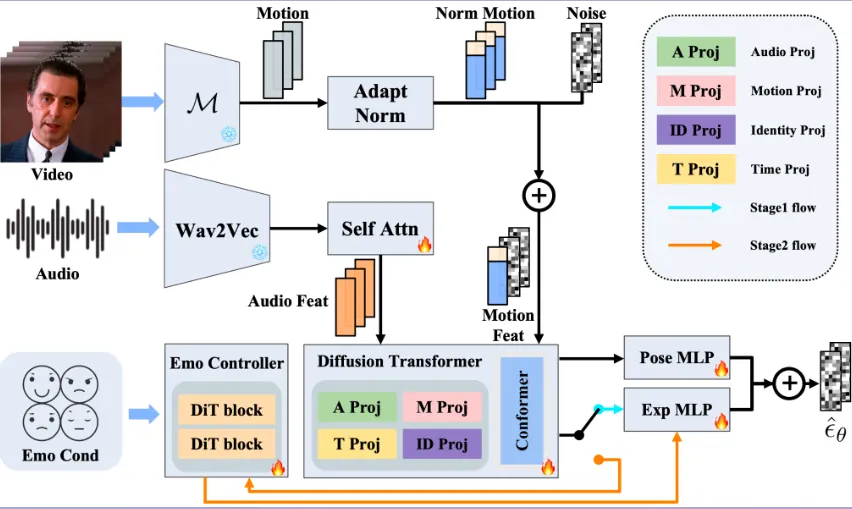
Playmate的技术实现包含多个创新模块,下面将深入解析其核心架构和算法原理。
1. 3D隐式空间构建
Playmate采用face-vid2vid和LivePortrait的面部表示框架,通过以下组件分离面部属性:
外观特征提取器(Appearance Feature Extractor, F):从源图像中提取静态外观特征
运动提取器(Motion Extractor, M):从驱动图像中提取运动信息(如关键点、旋转矩阵、平移向量等)
变形模块(Warping Module, W):将运动信息应用到源图像上
解码器(Decoder, G):生成最终动画视频
通过引入配对头部姿态与表情迁移损失(Pairwise Head Pose and Facial Dynamics Transfer Loss),模型能进一步优化对表情和头部姿态的独立控制能力。该损失函数通过计算源图像和目标图像在迁移后的感知差异(基于VGG19特征),有效提升属性解耦效果。
2. 运动解耦模块
为提升运动属性的解耦精度,Playmate采用自适应归一化(Adaptive Normalization)策略:
表情归一化:使用全局均值和标准差(基于整个训练数据集)对表情参数进行归一化
表情归一化公式:(x - μ_global)/σ_global
头部姿态归一化:针对每个身份独立计算均值和标准差,避免身份间的干扰
头部姿态归一化公式:(x - μ_id)/σ_id
这种分层归一化策略确保了不同身份的面部特征能够被正确处理,同时保持运动属性的独立性。
3. 扩散模型训练
Playmate基于扩散Transformer(Diffusion Transformer)生成运动序列,具体流程如下:
特征提取:利用预训练的Wav2Vec2模型提取音频特征,并通过自注意力机制对齐音频与运动特征
扩散过程:定义正向和反向马尔可夫链,逐步向目标运动数据添加高斯噪声,再通过Transformer模型预测并去除噪声
损失函数:最小化预测噪声与真实噪声的均方误差
L = ||ε - ε_θ(x_t, t, c_a, c_id)||^2
其中c_a和c_id分别为音频特征和身份特征,ε_θ为扩散Transformer的输出
4. 情绪控制模块
为实现精细的情绪控制,Playmate在第二阶段引入DiT块(Diffusion Transformer Blocks):
固定扩散Transformer参数,仅训练情绪控制器
采用双DiT块结构:
第一个DiT块接收音频特征和情绪条件
第二个DiT块进一步融合输出,并通过Exp-MLP生成最终运动序列
在推理阶段使用无分类器引导(Classifier-Free Guidance, CFG),通过调整音频条件(c_a)和情绪条件(c_e)的权重,平衡生成质量与多样性:
ε_θ(x_t, t, c_a, c_e) = w_a·ε_θ(x_t, t, c_a, ∅) + w_e·ε_θ(x_t, t, ∅, c_e) - ε_θ(x_t, t, ∅, ∅)

实验与评估
Playmate在多个数据集上进行了全面评估,证明了其技术优势。
1. 数据集与评估指标
数据集:AVSpeech、CelebV-Text、Acappella、MEAD、MAFW及自建数据集
评估指标:
FID(Frechet Inception Distance):衡量生成视频与真实视频的分布差异
FVD(Frechet Video Distance):衡量视频序列的动态差异
Sync-C/Sync-D:基于SyncNet的唇同步置信度分数和特征距离
CSIM(Cosine Similarity):衡量身份一致性
LPIPS(Learned Perceptual Image Patch Similarity):衡量图像感知相似度
2. 定量结果
在HDTF数据集上的对比实验显示:
| 方法 | FID↓ | FVD↓ | Sync-C↑ | Sync-D↓ | CSIM↑ | LPIPS↓ |
|---|---|---|---|---|---|---|
| Hallo | 30.484 | 288.479 | 7.923 | 7.531 | 0.804 | 0.139 |
| Hallo2 | 30.768 | 288.385 | 7.754 | 7.649 | 0.822 | 0.138 |
| MEMO | 27.713 | 299.493 | 8.059 | 7.473 | 0.840 | 0.132 |
| Sonic | 29.189 | 305.867 | 9.139 | 6.549 | 0.783 | 0.149 |
| JoyVASA | 29.581 | 306.683 | 8.522 | 7.215 | 0.781 | 0.157 |
| Playmate | 19.138 | 231.048 | 8.580 | 6.985 | 0.848 | 0.099 |
结果显示,Playmate在FID和FVD上显著优于现有方法,表明其生成视频的分布更接近真实数据。在身份保持(CSIM)和视觉质量(LPIPS)上也表现最佳,展示了算法的综合优势。
3. 定性评估
定性评估显示:
Playmate生成的视频在不同风格的肖像上表现出色,能够生成逼真的表情和自然的头部运动
算法对多种风格的肖像(真实人脸、动画和艺术肖像)都有良好的适应性
情绪控制模块能生成丰富多样的情感表达,满足不同场景需求
唇同步精度高,即使是快速对话或歌唱场景也能保持准确匹配
应用场景
Playmate的高质量生成能力和精细控制特性,使其在多个领域具有广泛应用前景:
1. 影视与动画制作
Playmate可以大幅降低影视动画制作中角色口型动画的制作成本。传统方法需要专业动画师逐帧调整,而Playmate只需输入音频即可自动生成精准的唇部动作,同时保持角色表情和姿态的艺术一致性。
在后期制作中,导演可以通过情绪控制模块实时调整角色表演,尝试不同的情感表达,而不必重新拍摄或制作动画,显著提升创作效率。
2. 虚拟数字人
Playmate已成功应用于"趣丸趣影"数字人产品,支持电商带货、虚拟主播等场景。其快速生成能力和高性价比特点,使得中小企业也能轻松创建个性化的数字人形象。
数字人客服是另一个潜在应用方向。Playmate的情绪控制功能可以让虚拟客服展现适当的情感表达,提升服务体验;而精准的唇同步则确保语音交互的自然流畅。
3. 游戏开发
游戏中的NPC对话系统可以集成Playmate技术,实现动态面部动画。相比传统的 blendshape 方法,Playmate生成的动画更加自然丰富,且能根据对话内容自动调整情绪表达。
角色创建系统也可以利用Playmate的能力,允许玩家上传自定义肖像,并为其赋予生动的面部动画,增强游戏的个性化体验。
4. 社交与娱乐
Playmate的"照片唱歌"功能具有很高的娱乐价值,用户可以将自己或朋友的照片与喜爱的歌曲结合,创建个性化音乐视频。
在教育领域,语言学习应用可以利用Playmate生成发音示范动画,帮助学习者观察标准的口型动作;历史教学则可以"复活"历史人物肖像,使其讲述自己的故事。
相关链接
Playmate项目提供了丰富的官方资源,方便研究者与开发者了解和使用该技术:
论文地址:https://arxiv.org/pdf/2502.07203
项目网站:https://playmate111.github.io/Playmate/
GitHub地址:https://github.com/Playmate111/Playmate
总结
Playmate是广州趣丸科技团队提出的创新性肖像动画生成框架,通过3D隐式空间引导扩散模型和双阶段训练架构,实现了高质量、高可控的肖像视频生成。该项目在技术层面创新性地提出运动解耦模块和情绪控制机制,解决了音频驱动动画领域的三大核心挑战:唇同步不准确、控制灵活性不足和情感表达受限。实验证明,Playmate在视频质量(FID 19.138)、身份保持(CSIM 0.848)和唇同步(Sync-C 8.580)等关键指标上均优于现有方法,同时展现出对多种风格肖像的广泛适应性。该项目不仅具有重要的学术价值,其开源计划和技术成果也已成功应用于数字人产品,为影视制作、虚拟现实、互动媒体等领域提供了强大的技术支持。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/playmate.html


























