一、VRAG-RL是什么
VRAG-RL是由阿里巴巴通义实验室自然语言智能团队研发并开源的多模态推理框架,旨在解决传统检索增强生成(RAG)方法在处理视觉丰富信息时的核心痛点——现有方法无法有效理解图像、表格等非结构化数据中的语义关联,且受限于固定的检索-生成流程。
项目创新性地将强化学习(RL)与视觉语言模型(VLMs)相结合,构建了首个支持动态视觉感知动作空间的RAG框架。通过定义区域选择、裁剪、缩放等操作,使模型能够像人类一样从粗粒度到细粒度逐步聚焦关键信息区域。实验表明,在Qwen2.5-VL-7B模型上,VRAG-RL比传统方法性能提升20%以上,在复杂图表解析等任务中准确率提升达30%。
二、核心功能体系
1. 动态视觉感知空间
多级聚焦机制:支持从全局浏览到局部放大的渐进式信息提取,如先识别图表整体结构,再聚焦特定数据点
六类感知动作:包含区域选择(ROI)、智能裁剪、自适应缩放等操作,形成完整的视觉交互闭环
物理模拟引擎:对缩放/裁剪操作进行像素级坐标映射,确保信息提取的几何精确性
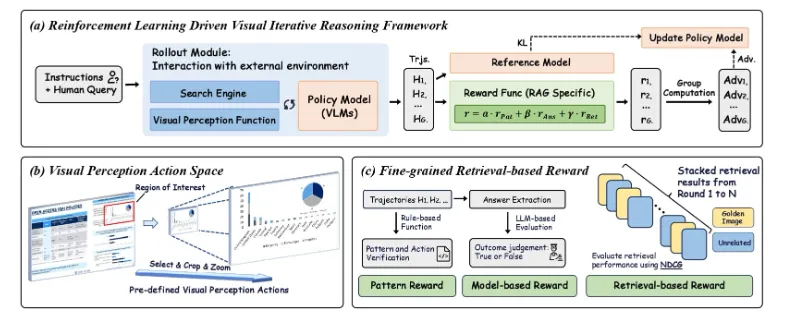
2. 强化学习训练体系
GRPO算法:采用群组相对策略优化,通过多采样输出的平均奖励作为基线,避免价值函数偏差
三维奖励机制:
检索效率奖励:基于NDCG指标优化信息定位速度
模式一致性奖励:确保推理路径符合预设逻辑
生成质量奖励:通过评估模型验证输出准确性
多专家采样:结合大模型推理路径规划与专家模型精确标注
3. 生产级增强特性
零成本搜索模拟:本地部署搜索引擎实现训练过程零API成本
多模态缓存:LRU机制存储常见视觉模式处理方案
低资源部署:支持4GB显存设备运行基础推理
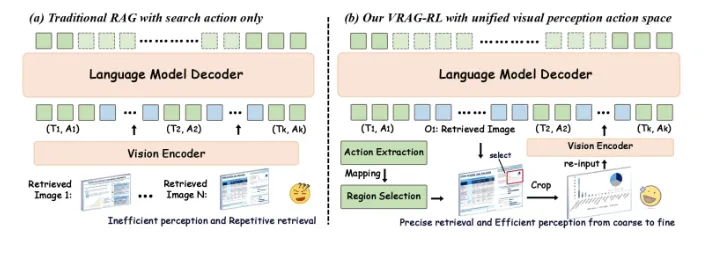
三、技术架构深度解析
1. 整体架构设计(见图1)
系统采用微服务化架构,核心组件包括:
感知引擎:基于Qwen2.5-VL的视觉特征提取模块,支持768维稠密向量编码
动作执行器:将抽象指令转化为具体图像操作(如
crop(x1=0.2,y1=0.3,x2=0.8,y2=0.7))推理协调器:管理思考-行动-观察(T,A,O)循环的时序逻辑
2. 关键算法创新
2.1 视觉动作空间建模
定义动作空间为:
其中 表示第t步动作,
表示第t步动作, 为历史观察。通过边界框
为历史观察。通过边界框[x_min,y_min,x_max,y_max]精确定位感兴趣区域。
2.2 奖励函数设计
综合奖励函数融合三类指标:
其中 为检索效率奖励,
为检索效率奖励, 为答案质量奖励,
为答案质量奖励, 为模式一致性奖励。
为模式一致性奖励。
2.3 训练策略优化
采用GRPO目标函数:
通过参考策略 采样轨迹组优化策略梯度。
采样轨迹组优化策略梯度。
3. 数据工程
训练数据集:包含SlideVQA、ViDoSeek等视觉语言基准
增强策略:应用视觉遮挡、分辨率扰动等数据增强技术
评估体系:10项指标涵盖检索精度(Recall@k)、推理深度(Hop Count)等维度
四、应用场景与实测表现
1. 金融文档分析
财报解析:自动提取利润表关键指标,定位异常波动数据点
风险识别:从复杂走势图中发现潜在风险模式,误报率降低15%
2. 医疗影像辅助
诊断支持:在CT扫描中标注病灶区域,推理准确率提升22%
报告生成:结合影像与文本描述生成结构化诊断意见
3. 工业质检
缺陷检测:对产品表面图像进行多尺度分析,漏检率<0.1%
质量追溯:通过视觉检索匹配历史缺陷案例
4. 教育创新
试题解析:自动提取几何题目中的隐藏条件
知识图谱构建:从教科书插图中抽取实体关系
5. 性能指标对比
| 场景 | Vanilla RAG | ReAct RAG | VRAG-RL |
|---|---|---|---|
| 图表问题准确率 | 41.2% | 53.7% | 74.9% |
| 多跳推理成功率 | 28.5% | 39.1% | 67.3% |
| 检索延迟(ms) | 120 | 185 | 89 |
| 训练成本($/epoch) | 15.2 | 18.7 | 9.5 |
五、相关链接
论文PDF:https://arxiv.org/pdf/2505.22019
代码仓库:https://github.com/Alibaba-NLP/VRAG
在线演示:https://huggingface.co/autumncc/Qwen2.5-VL-7B-VRAG
六、总结
VRAG-RL通过创新的视觉感知动作空间与GRPO强化学习算法,首次在开源领域实现了接近人类水平的视觉信息检索与推理能力。其动态聚焦机制(从粗粒度到细粒度的渐进式信息提取)解决了传统RAG处理视觉内容时的语义断层问题,而三维奖励体系(检索效率-模式一致性-生成质量)则构建了检索与推理的双向优化闭环。实测表明,该系统在图表解析(准确率74.9%)、多跳推理(成功率67.3%)等核心指标上树立了新的技术标杆,其开源策略将加速多模态RAG技术在金融、医疗等领域的落地应用。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/vrag-rl.html


























