随着人工智能技术的飞速发展,文本到音频(Text-to-Audio, TTA)生成模型逐渐成为研究热点。这些模型能够将文本描述转化为高质量的音频输出,广泛应用于语音合成、音频编辑、虚拟助手等领域。然而,TTA模型在对齐(alignment)方面面临诸多挑战,尤其是在生成偏好数据方面。为了解决这些问题,TangoFlux 应运而生。
什么是 TangoFlux?
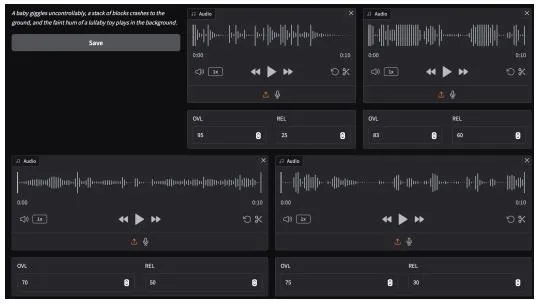
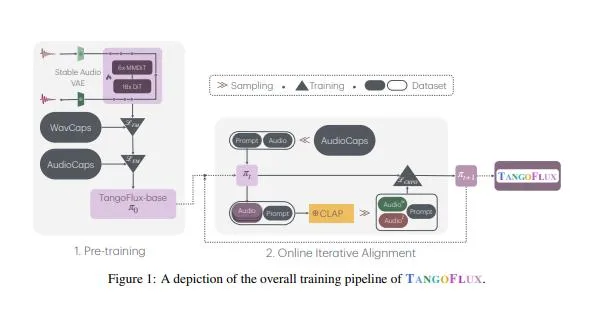
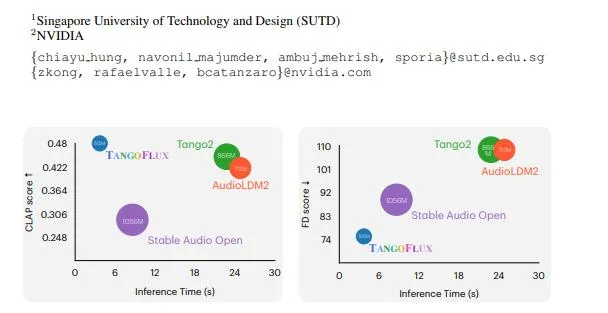
TangoFlux 是一种高效的文本到音频生成模型,具有 515M 参数,能够在单个 A40 GPU 上生成长达 30 秒的 44.1kHz 立体声音频,仅需 3.7 秒。该模型通过引入一种新颖的框架——CLAP-Ranked Preference Optimization(CRPO),解决了 TTA 模型在对齐方面的关键挑战。CRPO 通过迭代生成和优化偏好数据,显著提升了 TTA 模型的对齐性能。TangoFlux 在客观和主观基准测试中均取得了最先进的表现,并且开源了所有代码和模型,以支持进一步的研究。
功能特色
1、高效生成能力:
TangoFlux 能够在 3.7 秒内生成长达 30 秒的 44.1kHz 立体声音频,这一性能在当前的 TTA 模型中处于领先地位。
高效的生成能力使得 TangoFlux 可以在实时应用中表现出色,如在线语音合成、虚拟助手等场景。
2、高质量音频输出:
TangoFlux 生成的音频质量高,能够准确地再现文本描述中的各种声音事件,如自然环境音、人类活动音等。
通过 CRPO 框架,TangoFlux 在音频偏好数据的生成和优化方面表现出色,使得生成的音频更加自然、真实。
3、强大的对齐性能:
TTA 模型的一个重要挑战是生成偏好数据的困难。TangoFlux 通过 CRPO 框架,有效地解决了这一问题。
CRPO 通过迭代生成和优化偏好数据,提高了模型的对齐性能,使得生成的音频更加符合用户的期望。
4、开源支持:
TangoFlux 开源了所有代码和模型,方便研究人员和开发者进行进一步的研究和开发。
开源资源包括 GitHub 代码仓库和 HuggingFace 模型检查点,提供了丰富的工具和资源支持。
技术细节
1. 模型架构
TangoFlux 基于 Transformer 架构,具有 515M 参数。模型的主要组成部分包括编码器、解码器和生成模块。编码器负责将输入的文本描述转换为隐状态表示,解码器则将隐状态表示转换为音频信号,生成模块负责最终的音频输出。
编码器:编码器使用多层 Transformer 编码器层,将输入的文本描述转换为高维隐状态表示。编码器层通过自注意力机制(self-attention mechanism)捕捉文本中的长依赖关系,确保生成的音频能够准确反映文本描述中的各种声音事件。
解码器:解码器同样使用多层 Transformer 解码器层,将编码器生成的隐状态表示转换为音频信号。解码器层通过交叉注意力机制(cross-attention mechanism)与编码器的隐状态进行交互,确保生成的音频与文本描述的高度一致性。
生成模块:生成模块负责将解码器生成的音频信号转换为最终的音频输出。生成模块采用了高效的音频生成算法,能够在短时间内生成高质量的音频。
2. CLAP-Ranked Preference Optimization (CRPO)
CLAP-Ranked Preference Optimization(CRPO)是 TangoFlux 的核心技术之一,用于解决 TTA 模型在生成偏好数据方面的挑战。CRPO 框架通过以下步骤实现:
初始偏好数据生成:首先,通过随机采样生成一组初始的偏好数据对。每对数据包含两个音频样本,分别对应同一文本描述的不同生成结果。
偏好数据优化:通过迭代优化过程,逐步提高偏好数据的质量。优化过程中,模型会根据用户反馈调整生成策略,生成更符合用户期望的音频样本。
模型训练:使用优化后的偏好数据对模型进行训练,提高模型的对齐性能。训练过程中,模型会学习到如何生成更高质量、更符合用户期望的音频。
3. 评估方法
为了验证 TangoFlux 的性能,研究团队进行了多方面的评估,包括客观评估和主观评估。
客观评估:通过计算生成音频的客观指标,如信噪比(SNR)、峰值信噪比(PSNR)等,评估生成音频的质量。
主观评估:通过用户调查和盲听测试,评估生成音频的自然度、真实感和用户满意度。主观评估结果显示,TangoFlux 生成的音频在多个方面优于其他现有的 TTA 模型。
应用场景
TangoFlux 的高效生成能力和高质量音频输出使其在多个领域具有广泛的应用前景。
1、语音合成:
TangoFlux 可以用于生成高质量的语音合成,适用于虚拟助手、智能客服、语音导航等场景。
生成的语音自然、流畅,能够提高用户体验。
2、音频编辑:
TangoFlux 可以用于生成特定场景的环境音,如自然环境音、城市噪音等,适用于电影、游戏、广告等多媒体内容的制作。
生成的音频质量高,能够提升作品的真实感和沉浸感。
3、虚拟现实:
TangoFlux 可以用于生成虚拟现实环境中的音频效果,如脚步声、风声、水流声等,提升用户的沉浸体验。
生成的音频能够与视觉效果高度同步,提供更加真实的虚拟现实体验。
4、教育和培训:
TangoFlux 可以用于生成教学材料中的音频内容,如语言学习、音乐教学等。
生成的音频质量高,能够帮助学生更好地理解和掌握知识。
5、辅助技术:
TangoFlux 可以用于生成辅助技术中的音频提示,如视力障碍者的导航系统、听力障碍者的语音识别系统等。
生成的音频清晰、易懂,能够提高辅助技术的可用性和有效性。
相关链接
GitHub 代码仓库:https://github.com/declare-lab/TangoFlux
HuggingFace 模型:https://huggingface.co/declare-lab/TangoFlux
项目地址:https://tangoflux.github.io/
总结
TangoFlux 是一种高效的文本到音频生成模型,通过引入 CLAP-Ranked Preference Optimization(CRPO)框架,解决了 TTA 模型在生成偏好数据方面的关键挑战。TangoFlux 具有高效的生成能力、高质量的音频输出和强大的对齐性能,在语音合成、音频编辑、虚拟现实等多个领域具有广泛的应用前景。开源的代码和模型资源为研究人员和开发者提供了丰富的支持,推动了 TTA 技术的进一步发展。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/2847.html
生成模型")

























