在人工智能领域,语音理解语言模型(SULMs)正逐渐成为研究热点。随着技术的不断进步,语音理解模型在人机交互、智能家居、自动驾驶等多个领域展现出巨大的应用潜力。近日,西北工业大学ASLP实验室发布了开源语音理解模型OSUM,该模型结合了Whisper编码器和Qwen2语言模型,旨在探索在学术资源有限的情况下,如何有效训练和利用语音理解模型,以推动学术界的研究与创新。
OSUM是什么
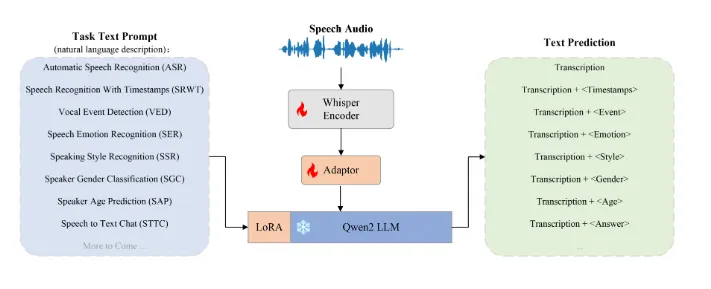
OSUM,全称为Open Speech Understanding Model,是由西北工业大学ASLP实验室研发的开源语音理解模型。该模型结合了Whisper编码器和Qwen2语言模型,旨在通过多任务学习的方式提升语音理解的能力。OSUM的发布不仅注重性能表现,还强调透明性,其训练方法和数据准备过程均已开放,旨在为学术界提供有价值的参考与指导。
功能特色
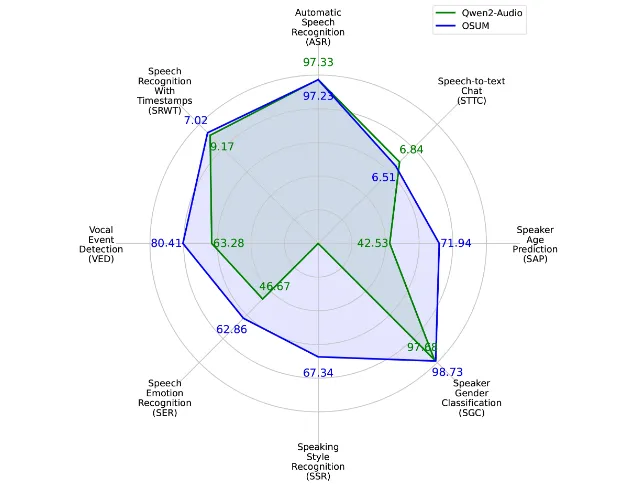
多任务支持:OSUM支持多种语音理解任务,包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话人性别分类(SGC)、说话人年龄预测(SAP)及语音转文本聊天(STTC)。这种多任务支持的能力使得OSUM能够在不同的应用场景下展现出强大的适应能力。
高效稳定的训练策略:OSUM采用了ASR+X训练策略,能够在进行目标任务的同时高效稳定地优化语音识别。这种训练策略不仅提高了模型的性能,还使得模型在多任务学习中的表现更加优异。
数据透明性:OSUM的训练方法和数据准备过程均已开放,这为学术界的研究者提供了宝贵的资源。通过公开这些数据和方法,OSUM旨在促进语音理解技术的研究与创新,加速技术的应用与推广。
技术细节
模型架构:OSUM模型融合了Whisper编码器和Qwen2语言模型。Whisper编码器是一个高效的语音编码器,能够将语音信号转换成高质量的语音特征表示。而Qwen2语言模型则是一个强大的语言模型,能够处理和理解自然语言文本。通过将这两个模型结合起来,OSUM能够实现高效的语音理解。
训练策略:OSUM采用了ASR+X训练策略,其中ASR表示语音识别任务,X表示其他语音理解任务。在训练过程中,OSUM会同时优化语音识别任务和其他语音理解任务,从而实现多任务学习的能力。这种训练策略不仅能够提高模型的性能,还使得模型在不同的任务之间具有更好的泛化能力。
数据集:OSUM的训练数据集已经扩展至50.5K小时,其中包括3000小时的语音性别分类数据和6800小时的说话人年龄预测数据。这些数据的扩展使得模型在各种任务中的表现更加优异。同时,OSUM还公开了数据准备和预处理方法,为学术界的研究者提供了宝贵的资源。
应用场景
人机交互:在人机交互领域,OSUM可以应用于语音助手、智能家居等场景。通过识别用户的语音指令并理解其意图,OSUM能够提供更加智能和便捷的人机交互体验。
自动驾驶:在自动驾驶领域,OSUM可以应用于语音导航、语音控制等场景。通过识别驾驶员的语音指令并理解其意图,OSUM能够提供更加安全和便捷的驾驶体验。
医疗健康:在医疗健康领域,OSUM可以应用于语音病历记录、语音诊断辅助等场景。通过识别医生和患者的语音信息并理解其意图,OSUM能够提高医疗服务的效率和质量。
教育娱乐:在教育娱乐领域,OSUM可以应用于语音教学、语音游戏等场景。通过识别用户的语音指令并理解其意图,OSUM能够提供更加个性化和有趣的教育娱乐体验。
相关链接
开源地址:OSUM GitHub
技术报告:OSUM 技术报告 v2.0
总结
OSUM作为一个开源的语音理解模型,在功能特色、技术细节、应用场景等方面均展现出强大的潜力。通过多任务学习的能力和高效稳定的训练策略,OSUM能够在不同的应用场景下提供智能和便捷的语音理解服务。同时,OSUM还公开了数据准备和训练方法论,为学术界的研究者提供了宝贵的资源。
本文由@ai资讯 原创发布。
该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.zhanid.com/news/3277.html




:通过反向工程实现")
 支持人声分割")




















